
关于Pandas中最难的pivot_table,stack,unstack详解!
简介
虽然大多数Pandas表达式读起来都像英语,但有时你会遇到真正让人头疼的表达式。是的,它们都有直观的名字,比如cut或pivot,但似乎让人无法理解。
因此,我决定写一系列文章,专门介绍我认为最难的Pandas函数。本文将详细地解释其中的三个函数:pivot_table、stack和unstack。如果你想了解更多关于编程的相关内容,可以阅读以下这些文章:
Meta正在做上帝的工作:向世界发布令人震惊的优秀编程模型!
畅销编程书籍中的10个编码秘密
Mojo:比Python快35000倍的AI编程语言
作为一个数据科学家/分析师,不要重复这5个编程错误
让我们开始吧!
安装
# Load necessary libraries
import pandas as pd
import seaborn as sns
import numpy as np
# Ignore warnings
import warnings
warnings.filterwarnings('ignore')
# Enable multiple cell outputs
from IPython.core.interactiveshell import InteractiveShell
InteractiveShell.ast_node_interactivity = 'all'将Pandas中的pivot_table()与groupby()进行比较
应该有一种——最好只有一种——显而易见的方法。
以上是Python禅宗的一句话。Python希望针对一个问题只有一个明显的解决方案。但是,pandas故意避免了这一点。在pandas中,一个操作往往有多种方法。
pivot_table()就是一个例子。它是groupby()函数的完整替代品,有时甚至是一个更出色的替代品。groupby()返回一个Series对象,而pivot_table()则给出一个易于操作的数据帧。
让我们用这两个函数来解决一个问题并给出解决方案。我将从seaborn中加载tips数据集:
tips = sns.load_dataset('tips')
tips.head()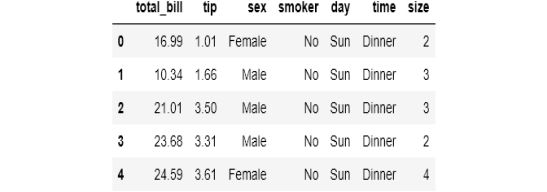
我们想找出每个性别的所有账单金额的总和。
# Using groupby
result = tips.groupby('sex')['total_bill'].sum()
>>> type(result)
pandas.core.series.Series
>>> result
sex
Male 3256.82
Female 1570.95
Name: total_bill, dtype: float64
# Using pivot_table
result_pivot = tips.pivot_table(values='total_bill', index='sex', aggfunc=np.sum)
>>> type(result_pivot)
pandas.core.frame.DataFrame
>>> result_pivot
让我们比较一下这两个函数的语法。在groupby()中,我们将要分组的列放在括号中,而在pivot_table()中,等价的参数是index。在groupby()中,为了选择要聚合的列,我们使用括号进行子集选择,而在pivot_table()中,我们将其传递给values参数。最后,为了选择聚合函数,在groupby()中我们使用链式方法,而pivot_table()提供了aggfunc参数。
result = tips.groupby('sex')['total_bill'].sum().reset_index()
result
在我写一篇关于DS和ML项目设置的文章时,我研究了大量的笔记。令我惊讶的是,很多人使用groupby()函数,并使用reset_index()函数将groupby()的结果转换为数据框,接下来就让我们进一步探索一下原因。
如果你使用pivot_table()函数,就不必使用reset_index()函数将结果转换为数据框。groupby()函数的结果不像数据框那样容易处理。让我们看看如何按多列分组并使用多个函数进行聚合。
tips.groupby(['sex', 'day'])['total_bill']\
.agg([np.mean, np.median, np.sum]).reset_index()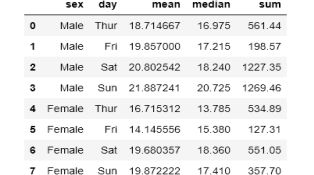
tips.pivot_table(values='total_bill',
index=['sex', 'day'],
aggfunc=[np.mean, np.median, np.sum])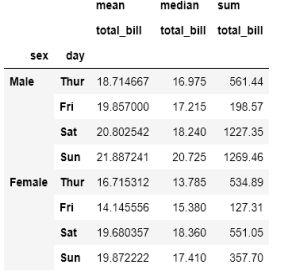
这两个函数都返回多列的数据帧。不过,尽管pivot_table()更适合单列数据,但在groupby结果上使用reset_index()会得到更漂亮的数据帧。也许这就是为什么Kagglers更喜欢使用groupby()。
在pivot_table()中,有时可以使用columns参数代替index(有时也可以同时使用这两个参数),将每个分组显示为一列。但如果给columns传递多个参数,结果将是一个只有一行的长数据帧。
groupby()和pivot_table()的另一个区别是fill_value参数。有时,当你按多个变量分组时,结果不会有匹配的单元格。在这种情况下,groupby()会显示NaN值,但在pivot_table()中可以控制这种行为。
tips.head()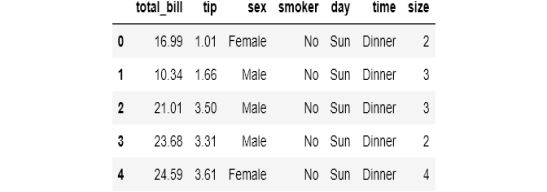
pivoted = tips.pivot_table(values='total_bill',
index=['sex', 'day'],
aggfunc=np.median,
fill_value=0)
>>> pivoted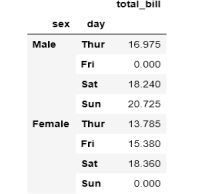
什么时候需要使用pivot_table()?正如我之前所说,有时它可以更好地替代groupby()。在句式方面,这也是个人偏好。一个明显的例子就是选择pivot_table(),因为它有一些groupby()中没有的其他参数。我已经介绍过fill_value,但还有margins等其他参数。你可以在文档中了解更多相关信息。
Pandas stack()
使用它时,stack()会返回一个重塑的多层索引数据帧。最内层是通过对数据帧的列进行透视创建的。为了更好地理解,我们最好举一个例子,我将加载cars数据集并对其进行子集化:
cars_small = sns.load_dataset('mpg')\
.set_index('name')[['weight', 'horsepower']].iloc[:10]
>>> cars_small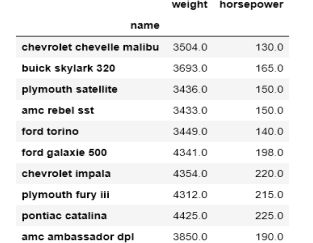
让我们看看如何透视数据帧,使列成为现在的索引:
当我们对这个数据帧使用stack()函数时,结果将是多级索引,外层是name,内层是weight和horsepower:
stacked_cars = cars_small.stack()
stacked_cars
name
chevrolet chevelle malibu weight 3504.0
horsepower 130.0
buick skylark 320 weight 3693.0
horsepower 165.0
plymouth satellite weight 3436.0
horsepower 150.0
amc rebel sst weight 3433.0
horsepower 150.0
ford torino weight 3449.0
horsepower 140.0
ford galaxie 500 weight 4341.0
horsepower 198.0
chevrolet impala weight 4354.0
horsepower 220.0
plymouth fury iii weight 4312.0
horsepower 215.0
pontiac catalina weight 4425.0
horsepower 225.0
amc ambassador dpl weight 3850.0
horsepower 190.0
dtype: float64在这里,原始数据帧只有单层列名。这就是为什么生成的数据帧是pandas.Series而不是数据帧。
请记住,stack()函数总是将列透视到内层索引。如果没有剩下的列,也就是说,如果最终数据是一个Series,stack()函数将不起作用。让我们尝试堆叠上述Series(双层堆叠):
stacked_cars.stack()AttributeError: 'Series' object has no attribute 'stack'当列名作为多级索引给出时,stack()会是一个更复杂的示例。让我们回到其中一个透视表:
multi_name = tips.pivot_table(values='total_bill', index=['sex', 'day'],
aggfunc=[np.mean, np.median, np.sum])
>>> multi_name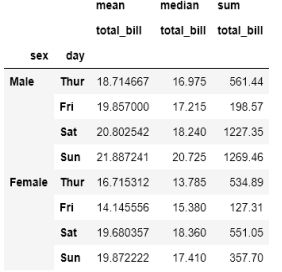
如你所见,列名有两级层次结构。你可以这样访问具有多级名称的列:
multi_name[('mean', 'total_bill')]
sex day
Male Thur 18.714667
Fri 19.857000
Sat 20.802542
Sun 21.887241
Female Thur 16.715312
Fri 14.145556
Sat 19.680357
Sun 19.872222
Name: (mean, total_bill), dtype: float64让我们在这个数据帧上使用stack()看看会发生什么:
multi_name.stack()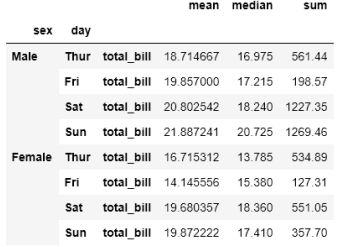
现在,作为内层列名的total_bill变成了索引。你可以控制要堆叠哪一级列名。让我们看看如何堆叠外层列名:
multi_name.stack(level=0)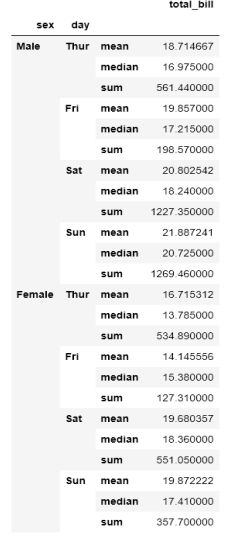
正如你所看到的,使用不同的级别可以得到不同形状的数据框。默认情况下,Level设置为1。
Pandas unstack()
顾名思义,unstack()的作用与stack()恰恰相反。它使用多级索引Series或数据帧,并将索引转为列。如果我们将堆叠的汽车系列解堆叠,就会得到原始的数据帧:
>>> print('Stacked Series:')
>>> stacked_cars
Stacked Series:
name
chevrolet chevelle malibu weight 3504.0
horsepower 130.0
buick skylark 320 weight 3693.0
horsepower 165.0
plymouth satellite weight 3436.0
horsepower 150.0
amc rebel sst weight 3433.0
horsepower 150.0
ford torino weight 3449.0
horsepower 140.0
ford galaxie 500 weight 4341.0
horsepower 198.0
chevrolet impala weight 4354.0
horsepower 220.0
plymouth fury iii weight 4312.0
horsepower 215.0
pontiac catalina weight 4425.0
horsepower 225.0
amc ambassador dpl weight 3850.0
horsepower 190.0
dtype: float64>>> print('Unstacked Dataframe:')
>>> stacked_cars.unstack()Unstacked Dataframe: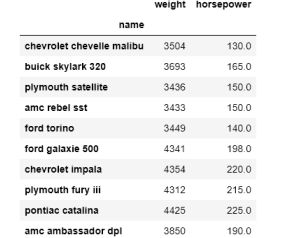
也许,在使用groupby()函数时,取消堆叠的作用最为明显。虽然按单个变量分组时无法进行解堆叠,但事实证明,解堆叠在按多个变量分组时非常有用。让我们回到tips数据集:
tips.head()
multiple_groups = tips.groupby(['sex', 'smoker', 'day', 'time'])['total_bill'].sum()
>>> multiple_groups
sex smoker day time
Male Yes Thur Lunch 191.71
Dinner NaN
Fri Lunch 34.16
Dinner 129.46
Sat Lunch NaN
Dinner 589.62
Sun Lunch NaN
Dinner 392.12
No Thur Lunch 369.73
Dinner NaN
Fri Lunch NaN
Dinner 34.95
Sat Lunch NaN
Dinner 637.73
Sun Lunch NaN
Dinner 877.34
Female Yes Thur Lunch 134.53
Dinner NaN
Fri Lunch 39.78
Dinner 48.80
Sat Lunch NaN
Dinner 304.00
Sun Lunch NaN
Dinner 66.16
No Thur Lunch 381.58
Dinner 18.78
Fri Lunch 15.98
Dinner 22.75
Sat Lunch NaN
Dinner 247.05
Sun Lunch NaN
Dinner 291.54
Name: total_bill, dtype: float64结果是一个具有4级索引的系列。这不是我们想要的。让我们取消堆叠,使其更易于使用:
multiple_groups.unstack()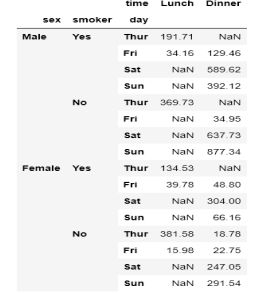
结果仍然有多级索引。这是因为unstack()一次只处理一个索引级。让我们再调用一次,得到一个只有单层索引的数据帧:
multiple_groups.unstack().unstack()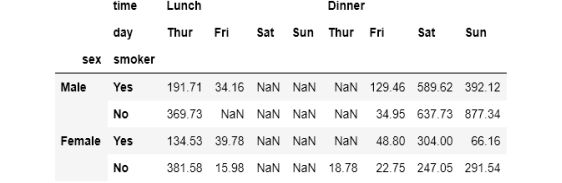
我想你已经看到了unstack()与groupby()一起使用时的效果。多级索引总是很难处理。除非万不得已,否则应尽量避免使用多级索引。其中一种方法就是使用unstack()。
虽然stack()并不常用,但我还是向你展示了它的基本句式和一般用法,以便你更好地掌握unstack()。
结论
你是否遇到过这样的问题:三个功能中的一个可以轻松解决,但你却不得不花几个小时重新开始?
如果有,我很同情你。如果没有,那么至少你知道今后应该怎么做了。
感谢你的阅读!你还可以订阅我们的YouTube频道,观看大量大数据行业相关公开课:https://www.youtube.com/channel/UCa8NLpvi70mHVsW4J_x9OeQ;在LinkedIn上关注我们,扩展你的人际网络!https://www.linkedin.com/company/dataapplab/
原文作者:Bex T.
翻译作者:Qing
美工编辑:过儿
校对审稿:Chuang
原文链接:https://pub.towardsai.net/the-hardest-of-pandas-pivot-table-stack-and-unstack-clearly-explained-3c37a6faac2c




