
当我们谈论机器学习时我们在谈论什么?
众所周知,NIPS Conference(Neural Information Processing Systems)是机器学习领域的热门会议之一。每年顶会都会有大量重量级的科研论文发表,从1987到2017年以来,已经有超过五万篇文章。这些论文针对机器学习,涵盖范围极为广泛,从神经网络到优化方法,应有尽有。
所以,作为一个数据分析的狂热分子,当然要了解机器学习圈当前比较热门的话题,才能做时代的弄潮儿鸭!让我们用code来分析这些论文,看看机器学习的新趋势吧!
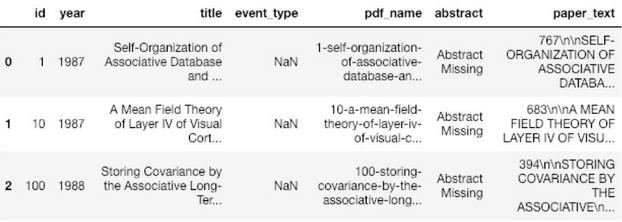
首先,老生常谈,把数据导入进去,并且观察数据的特征。一般而言,科研论文是由题目,摘要和正文组成的(在官方保存的PDF格式的论文中,图表和表格并没有被保存下来)。每篇文章都讨论了一个新颖的技术,或者基于之前技术所做的改良。这次分析,我们使用的是NLP方法。

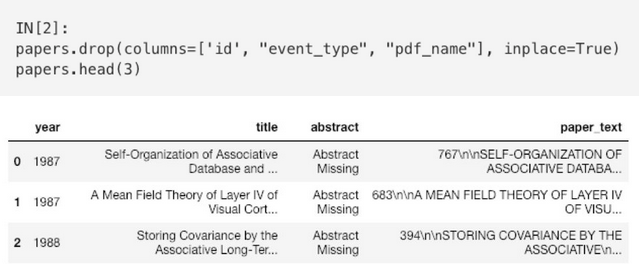
很明显,对于我们的分析而言,id,event_type和pdf_name对我们的预测无关紧要,应该删掉它们。我们只对与论文相关的文本数据和其发表的年份感兴趣。
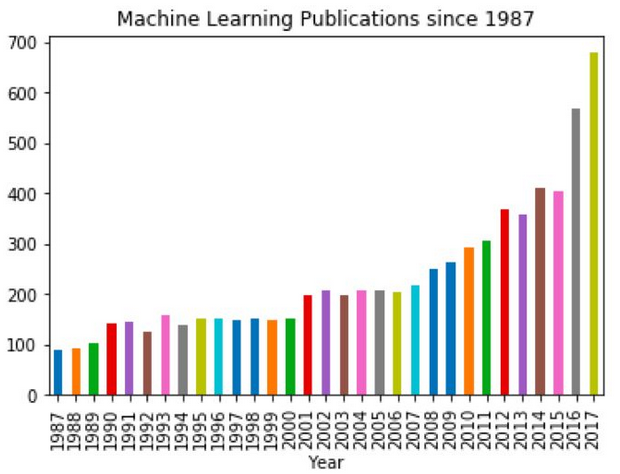
为了直观看出机器学习受欢迎程度近年来的爆炸性增长💥,我们可以根据年份和每年发表论文的数量绘图,你就会明白什么叫“革命”了😊。从2007年到2017年,论文发表的数量翻了接近三倍。当然,这种弹簧式的增长,与计算机算力的提升,数据量的增加,算法的改良是分不开的。

在分析机器学习的趋势之前,我们需要对文本进行适当地处理。比如,用正则表达式的方法删去标点符号,把字母都变成小写。
为了确认我们到目前为止的分析是没有问题的,我们可以绘制一个词云图来看一下。可视化是确认我们的分析方向是否正确的关键哦~ 在错误的道路上越走越远可就南辕北辙了。而且,它还能帮助我们看出,在进行深度分析之前,是否还需要其他的数据预处理。

LDA分析可以从大量文字中,统计分析出这篇文章的主题,甚至小话题,也就是有哪些词通常会频繁出现,一起出现。
但是,LDA无法直接对文字进行处理。我们需要先把文本数据转化成向量。向量的每个数值都表示一个单词在文章中出现的次数。所以,如果我们把一个词汇表转换成一个向量,那么向量的长度就等于词汇表中出现的单词个数。比如,‘Analyzing machine learning trends with neural networks.’ 可能会被转化成(1,0,1,0,1,1,0)。
依据这个原理,我们就可以统计出最常出现的10个单词。可想而知,这个结果应该和上面的词云图相同才对。

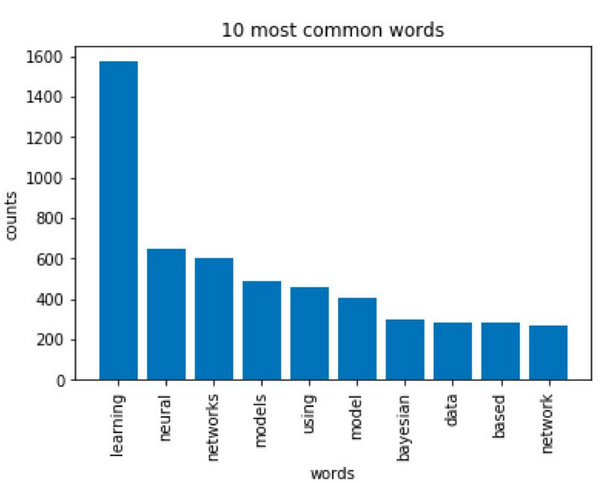
是吧,这个结果和词云图是一致的,出现最频繁的词条确实是learning, neural 和networks等等。
分析完词条,热身之后,我们终于要分析论文们的常见话题了。值得一提的是,接下来的分析方法同样适用于数据,照葫芦画瓢就可以啦。
唯一需要进行微调的参数就是‘热门话题数量’。通常,需要以模型的复杂度为标准决定一次应该挑选出多少热门话题。尝试不同的参数,找出最合适的‘热门话题数量’。通过如下的分析,我们可以发现,大部分顶会论文的话题都是与这些相关:
> Neural networks
> Reinforcement learning
> Kernel methods
> Gaussian processes
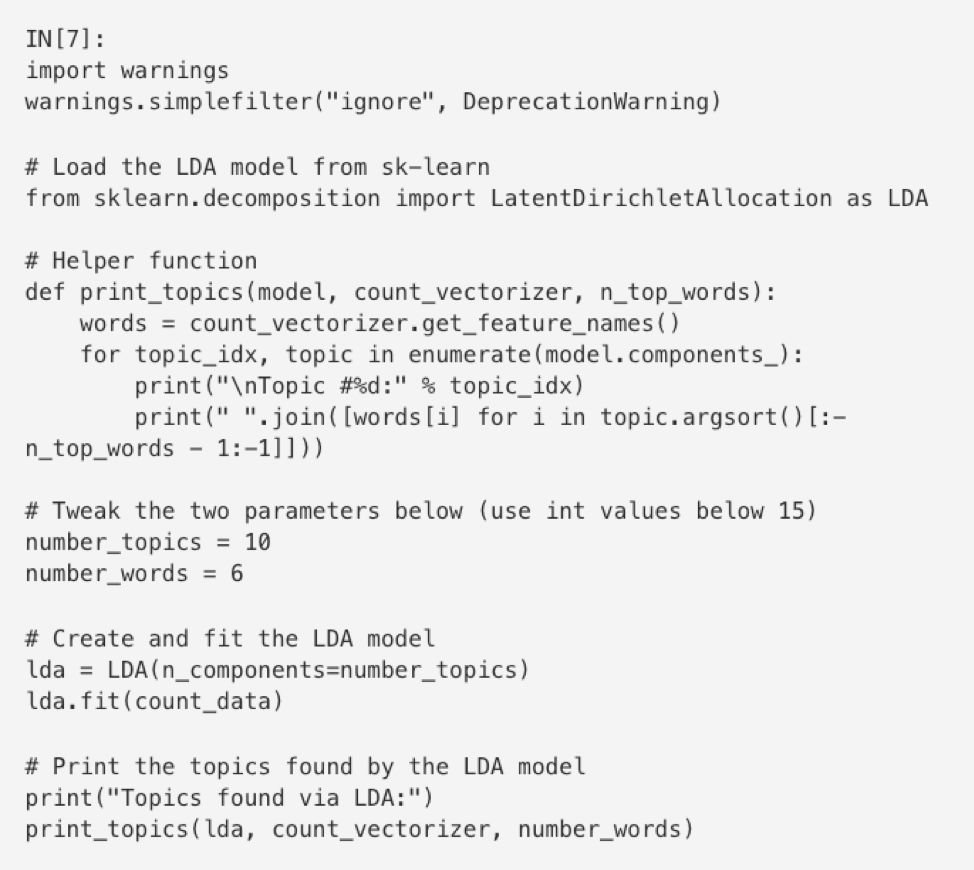

这些热词和热门话题就是我们努力的方向呀!快朝着这些方向跑步吧🏃!想成为一个数据科学家,就要时刻了解行业大趋势,在了解传统技术的基础上,学习最新的技术。
原文作者:Akash Dubey
翻译作者:Zihuan
美工编辑:喝豆奶的Narcia
校对审稿:卡里
原文链接:https://towardsdatascience.com/the-hottest-topics-in-machine-learning-53b5ebd02e44





