
为什么BI 对数据科学家很重要?
实际上,我在数据科学实习期间就接触过商业智能,但这也不是唯一一次。在这之前,我在一家 ICT 公司的另一职位实习中,又接触了一次。
在大学期间,我从没学过这方面的课程,加上很多新概念在网络上的资源并不多,所以想要了解商业智能并不容易。那么,什么是商业智能?为什么通常是在上班族而不是在学生的时候接触到它?如果你想了解更多数据分析相关内容,可以阅读以下这些文章:
2021年数据科学家,最需要这7个技能!
数据科学家,知道这些统计知识就对了
Sampling 101:详解统计学中的抽样技术
AB 测试应用:AB Testing在社交领域的实践及挑战
商业智能(Business Intelligence)是一门使用统计学和机器学习等技术来分析公司数据的学科,目的是提高竞争力。公司拥有大量数据,需要从这些数据中提取有用的信息来提高竞争力。为此,他们投资于这类研究,寻找能够提取这些信息的方法。例如,像亚马逊这样的大公司就经常使用商业智能。这类公司需要了解客户的喜好,针对客户进行专门的分析,找到能够满足客户需求的产品。
有许多自动和半自动工具可以管理如此庞大的数据量。在讨论相关工具之前,我们需要区分要分析的数据类型。第一种类型称为结构化数据(Structured Data),指的是易于从计算机读取的数据,通常是数字数据,例如房屋的价格、人的年龄等。另一种更常见的数据类型称为非结构化数据(Unstructured data),指的是计算机无法自动识别的数据,例如文本、图像、视频。大部分数据都是非结构化的,需要事先进行预处理。
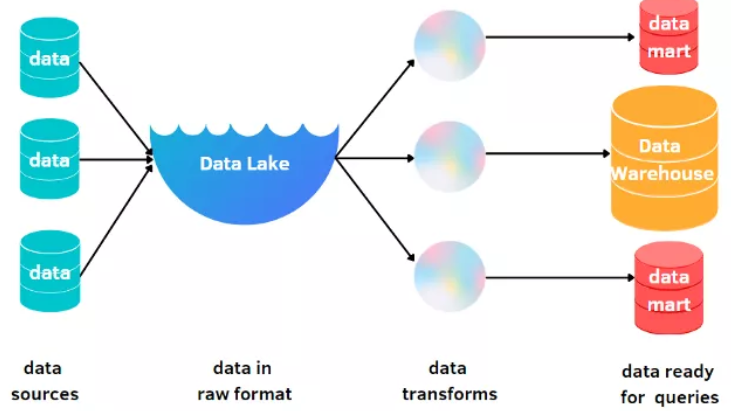
存储这些数据的最常见的存储库是数据仓库和数据湖。数据仓库仅存储结构化数据,而数据湖可以储存两种类型的数据。下面,我将解释数据仓库和数据湖的基本概念。根据目的不同,某一个存储库可能会比另一个更好。要考虑到这些方面,才能很好地了解这些基础设施的含义。
目录
- 1. 数据仓库
- 2. 数据集市
- 3. OLTP 与 OLAP
- 4. ETL
- 5. Star 与 Snowflake 模式
- 6. 数据湖
- 7. 从 ETL 到 ELT
- 8. 批处理与流处理
1. 数据仓库
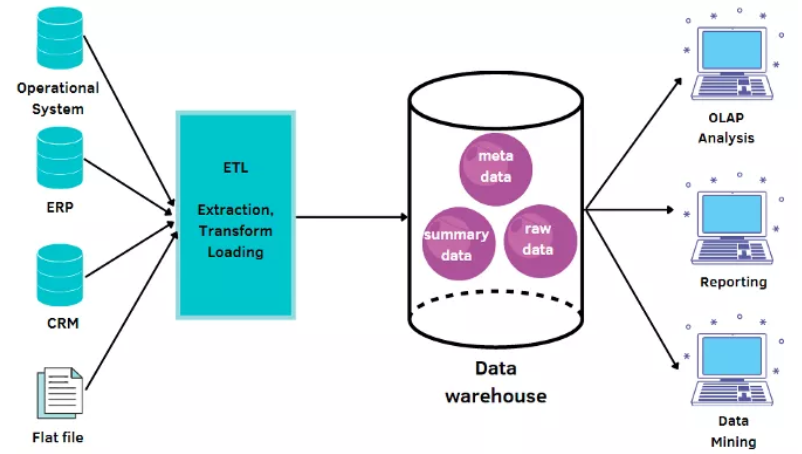
结构化和已处理的数据会存储在数据仓库中。数据仓库已经有20年历史,是许多公司(例如银行和金融公司)的中心信息存储库。这类数据具有预定义的架构,可以进行简单的查询,但由于某些原因,需要更新来更改架构时会出现复杂情况。这个过程会用到提取、转换、和加载 (ETL) 。从名称中,你可以推断出来,这个过程为提取、转换数据并将其加载到存储库中。数据仓库存储数据有三种:
- 元数据(Metadata)描述有关数据仓库的信息,以及了解所存储数据的详细信息的数据。
- 汇总数据(Summary data)是数据仓库管理员生成的汇总/汇总数据,有助于加快查询性能。
- 原始数据(Raw Data)是存储在数据仓库中的未经处理的数据。
2. 数据集市(Data Marts)
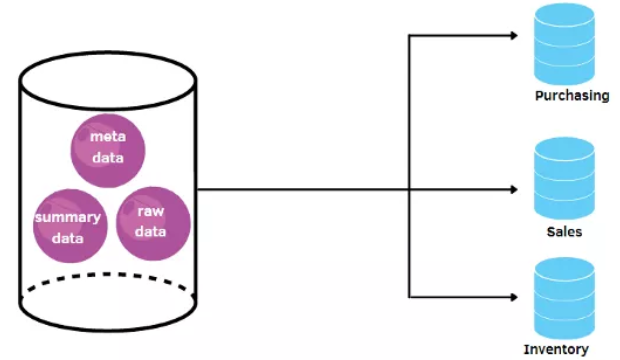
由于数据仓库很大,而且构建时间较长,因此也就出现了较小的存储库,即数据集市。数据集市们包含有关特定部门的信息,更加有针对性。
3. OLTP 与 OLAP
OLTP/在线交易处理(OnLine Transaction Processing)可用于管理大量的事务,例如现有事务的插入、删除、更新操作。与 OLTP 不同的是,OLAP/在线分析处理(OnLine Analytical Processing)旨在运行分析查询,从多维角度过滤和聚合数据。一般来说,OLTP用于数据预处理,OLAP用于数据分析。
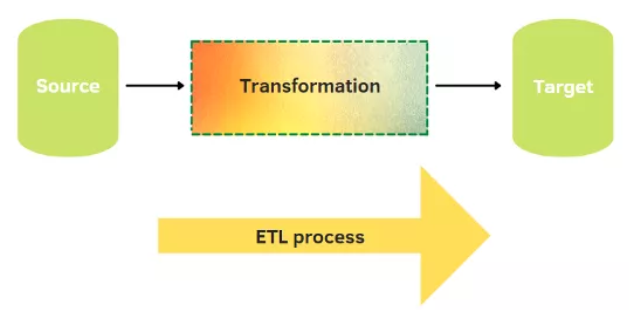
正如我之前所说,ETL 是一个聚合和处理的过程,可以构建数据仓库。操作过程主要分为以下三步:
- 提取:第一步是从各种来源提取数据,例如 CSV、JSON 和 XML 文件、非关系和关系数据库、API。
- 转换:它包括将数据转换为可用于查询和分析的格式,包括一些操作,例如清理、验证、连接、创建聚合、删除重复项。
- 加载:将数据保存到最终目的地,即数据仓库。它可能每分钟,每小时,每天,甚至每周都在运行。加载的数据越多,分析就越精确。
4. 星型(Star)模式与雪花(Snowflake)模式
数据仓库系统使用多维模式保存数据。此模式可用于管理大量数据以进行分析。广泛应用的模式主要有两种。
模式与雪花(Snowflake)模式.png)
第一个是星型模式。之所以以Star命名,是因为它的结构类似于星星之间的关系。中间是事实表(fact table),周围是维度表(dimension tables)。事实表包含维度列和事实列。维度列构成foreign key,连接事实表与维度表。这些foreign key是维度表对应的primary key。因此,维表和事实表之间的join是通过foreign key进行的,而维度表之间并没有连接。Star Schema 能够更加清晰地解释存储空间,运行时也更高效。
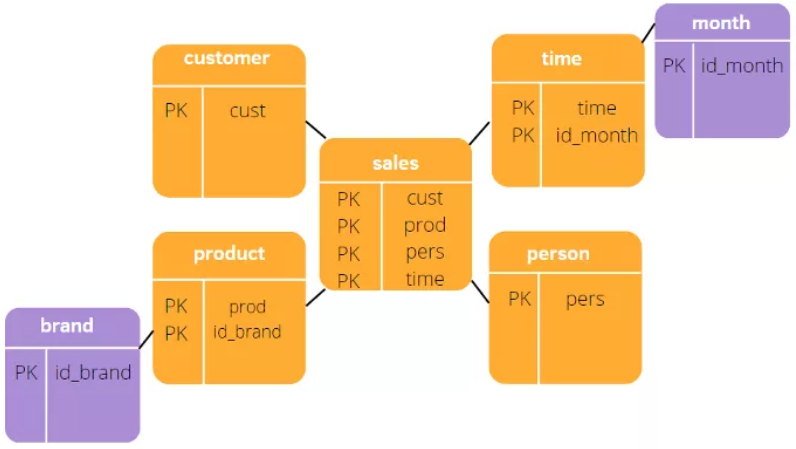
第二种也是最后一种类型,雪花模式。它的结构类似于雪花。这种模型的优点是它可以添加维度,并使用更少的存储空间。但同时,表格更多,需要更多查询,从而影响性能。由于这些原因,雪花模式需要更多的维护工作。
5.数据湖
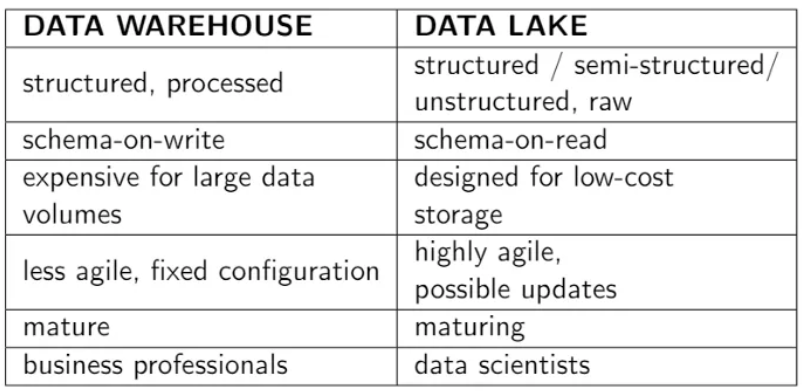
与数据仓库不同,数据湖没有那么复杂,因为它存储所有类型的数据,包括原始数据、结构化数据和非结构化数据。它能在没有模式的情况下保留数据。可以对过去、当前和未来信息进行分析,因为数据永远不会被删除。数据湖专为低成本存储而设计,从而消除了存储的限制。
数据湖比数据仓库更晚出现,因为它本质上还是一个数据仓库,所以不太容易投入使用。每项技术都有不同的终端用户。数据科学家或资深数据专家能够通过数据湖,从数据中提取有用信息,而业务分析师只能使用数据仓库。此外,数据湖使用 ELT 流程,而不是使用 ETL 作为数据仓库。
6. 从 ETL 到 ELT
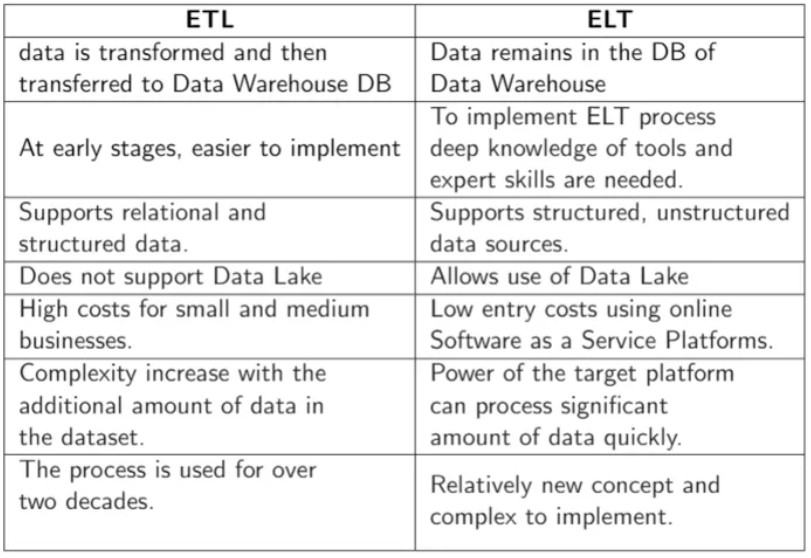
ELT 过程代表提取、加载、转换。这是新的范式。首先,数据会被提取并存储在数据湖中,没有任何转换过程。必要时才会处理数据湖中的数据。但是以这种方式保留的所有数据会导致内存和查找有用信息的效率问题。这种方法通常应用于非sql的数据库,如MongoDB和Hadoop集群。
7. 批处理与流处理
批处理(Batch processing)是一次性处理一组或一批中的大量数据。这些数据在过去已经被存储过了。与批处理不同,流处理(Streaming Processing)被用于实时处理数据。批处理技术有Azure Databricks 和 Azure Synapse Analytics,而流处理有 Apache Spark 和 Apache Kafka。当我们考虑机器学习环境时,模型的训练通常是“分批”进行的。一旦生产发布了 ML 模型,它就会预测流内的模态。
结语
恭喜!现在,你已大致了解商业智能中的主要概念。一开始,看到这些新词,你可能会很焦虑。但经过一番努力,他们终将烟消云散。你只需要耐心并专注于基本概念。与公司数据分析有关的一切都与商业智能有关。机器学习算法可以用于从数据中提取数据信息,并做出决策,这些都将影响公司发展。
希望你喜欢这篇文章。祝你今天过得愉快!你还可以订阅我们的YouTube频道,观看大量数据科学相关公开课:https://www.youtube.com/channel/UCa8NLpvi70mHVsW4J_x9OeQ;在LinkedIn上关注我们,扩展你的人际网络!https://www.linkedin.com/company/dataapplab/
原文作者:Eugenia Anello
翻译作者:Lia
美工编辑:过儿
校对审稿:Jiawei Tong
原文链接:https://pub.towardsai.net/why-is-business-intelligence-useful-for-a-data-scientist-2d9d21167e2f





