
AB 测试应用:AB Testing在社交领域的实践及挑战
A/B测试的概念听起来其实很简单:把用户随机分配到实验组或对照组,对实验组的个体进行处理,然后对比对照组,检查实验组的用户是否表现出了行为变化。但是,如果用户之间是彼此交互的,我们很难严格区分出实验组和对照组,这该怎么办呢?
很多人都知道,包括Facebook,Google和 LinkedIn在内的很多公司都在A/B测试工作上花了很大功夫。但是,鉴于产品的高度互连性,这些公司都面临着上述的问题。如果处理不好,就会在实验结果中造成偏差,甚至会损害用户体验。那么,这些公司是如何解决这类问题的呢?如果你想了解更多数据分析相关内容,还可以阅读以下这些文章:
不可不知的数据科学基础 ——AB Testing
如何在不花一分钱进行A/B Testing?一起来薅资本主义羊毛!
200万人阅读的AB Testing好文
在社交网络中运用A/B测试的挑战
在运用A/B测试时,通常会假设任意一个个体的潜在结果,是不会随其他个体是否接受处理而改变的。而且,每个个体受到的处理和潜在结果之间是定义良好的函数,这就是我们常说的个体处理稳定性假设(SUTVA)。
但是,假设一个大型社交网络平台(例如LinkedIn或Facebook)想要测试一种改进的算法,使其推荐的内容更贴合用户,增进与用户间的内容交互。如果实验组的用户A与对照组中的用户B彼此交互,那么用户A的行为变化可能会影响用户B的行为。用户A的推荐内容可能会更贴合用户A的喜好,导致用户A共享更多的帖子、图片和文章。最终这可能也会对用户B产生影响,使他产生相同的行为变化,即使用户B并没有接受实验组的处理。
对实验组进行的处理成功与否,常常通过实验组与对照组之间的平均结果的差值来衡量,例如转化率的差值,这就是所谓的平均处理效应(ATE)。在社交网络中运用A/B测试,溢出效应(Spillover effects)会使平均处理效应产生偏差,因为我们无法准确把握对实验组进行的处理带来的行为变化。比如我们刚刚讨论的社交网络平台的推荐内容算法测试,溢出效应使得不仅实验组的推荐内容更贴合用户,而且对照组的推荐内容也随之更贴合用户。这是因为对照组的用户通过与实验组的用户交互,也受到了实验组的处理的影响。因此,如果在社交网络中运用传统的A/B测试方法,溢出效应会大大削弱实验组处理的积极效果,可能最终会导致错误的结论。
除了有统计结果偏差的风险外,在社交网络或存在用户协作的应用程序中进行A/B测试还可能带来一些用户体验方面的问题。例如,在视频聊天软件或用户高度协作的软件(如Google Docs)中测试新功能时,如果在视频通话时或在同一文档上进行协作的用户之间可操作的功能不同,使用过程中就可能出现操作混乱,恶化用户体验。
总的来说,A/B测试的经典方法可能会产生有偏差的统计结果,误导业务决策,同时严重损害用户体验。
聚类取样(Cluster Sampling)
聚类取样(Cluster Sampling)又被称为整群抽样,是处理溢出效应的常用方法。聚类取样是将总体中各单位归并成若干个互不交叉、互不重复的集合,称为集群或群;然后以群为抽样单位来抽取样本的一种抽样方式。应用聚类取样时,各群必须有较好的代表性。
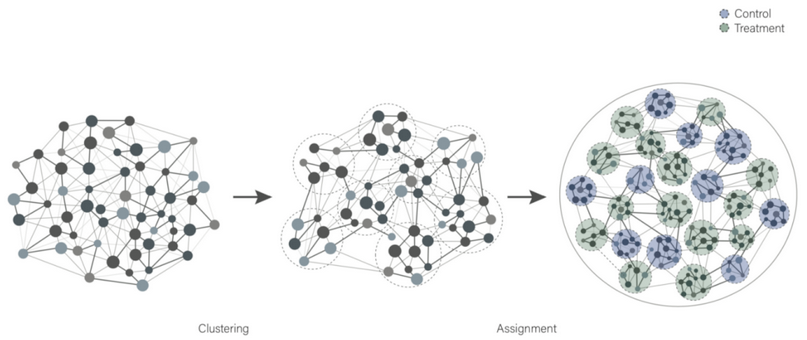
分组时,要尽量使组与组之间的信息流最小,这是一个不小的难点。不过,有很多聚类算法可以解决这一问题,比如e-net。E-net的概念大致如下:
- 1. 查找k个节点,作为聚类中心,它们之间的距离要大于特定阈值。
- 2. 将其余节点随机分配到距离其最近的聚类中心。
当然,在像Google Cloud Platform之类的协作应用程序中,还有一些更具体的方法来创建这些集群。由于彼此交互的用户数量受他们一起工作的项目数量的限制,可以创建一个在相同项目上工作的用户集群,来把集群之间的溢出效应降低到接近于0(但如果某一集群中的用户加入了另一个集群中的用户创建的新项目,那么溢出效应仍会发生)。
不过,聚类取样也存在一定的挑战。在(社交)网络中进行聚类取样分组时,需要在集群大小和集群数量之间权衡取舍。一方面,集群数量越多,A/B测试的统计精度越高。另一方面,用户组中完全不同的集群数量越多,这些集群之间就越容易产生交叉,溢出效应影响就越大。几个例子,如果只有一两个集群,那么溢出效应将比有一百个或更多集群小得多。除此之外,各个集群的大小也要相同,这有助于减少差异,增加测试的有效性。
A/B测试集群
建好了集群后,就可以将集群分配给控制或处理单元,在集群上进行测试。转化率这类指标会首先在集群水平上计算得到,然后取平均值来得到实验组水平上的值。最终,这些结果可以用来计算平均处理效果。

通常,这个方法也可用于证明网络效应的存在。比如,在进行实验时,可以同时运行用户级别上随机化的A/B测试,和集群级别上随机化的A/B测试,如果两种测试之间的平均处理效果存在显着差异,那么就可以证明网络效应的存在。
其他挑战
在集群而不是用户级别上进行随机化,只能解决在社交网络中进行A/B测试时出现的部分问题。另一个要考虑的问题是,将用户分成集群时,用户之间连接的强度和方向。与Facebook、LinkedIn相比,Instagram和Twitter的网络结构是截然不同的。在这些网络中,发挥重要作用的影响者是相对较小的用户群体,他们能够对许多用户产生重大影响。同时,这些连接中的大多数都朝着一个方向发展:影响者可以对其粉丝产生影响,反之则不然。
想象一种极端的情况:一个用户非常有名,网络中的所有其他用户都在关注他。无论如何划分网络,该用户都能影响所有用户。但是,在正常情况下,仅仅通过将具有最接近连接的用户分组到集群中,是并不会降低溢出效应的。解决这一问题的一种方法,是把影响者作为初始聚类中心,并通过多数表决把其余用户分配给这些聚类。
结论
A/B测试是一个广泛使用且经过充分研究的领域。但是,在社交网络中进行A/B测试所面临的挑战尚未被解决,仍需进行深入研究。例如寻找正确的聚类方法、平均处理效应的理想估计量等等。不过,鉴于A/B测试是Facebook和Twitter等大型科技公司所有产品开发活动的核心,这些公司一定会投入大量人力,努力开发出克服这些挑战的新方法。我们也需要持续关注和学习A/B测试的最新进展。感谢你的阅读,希望这篇关于AB Testing的文章对你有所帮助。你还可以订阅我们的YouTube频道,观看大量数据科学相关公开课:https://www.youtube.com/channel/UCa8NLpvi70mHVsW4J_x9OeQ;在LinkedIn上关注我们,扩展你的人际网络!https://www.linkedin.com/company/dataapplab/
原文作者:Dennis Meisner
翻译作者:Haoran Qiu
美工编辑:过儿
校对审稿:Jiawei Tong
原文链接:https://towardsdatascience.com/ab-testing-challenges-in-social-networks-e67611c92916





