
Machine Learning Model:建立机器学习模型的四个概念
我喜欢写作的原因之一,是它让我有机会回顾过去,反思我的经历,并思考哪些行得通,哪些行不通。

在过去的 3 个月里,我收到的任务是构建一个机器学习模型,用来预测产品是否应该进行 RMA 处理。这是我开发的第一个“正式”的机器学习模型——我用引号说“正式”,因为这是我第一个创造实际商业价值的模型。
鉴于这是我的第一个“正式”模型,我非常天真的误以为,构建模型的过程将会是这样:
然而,实际上,构建模型的过程更像这样:
总的来说,这个模型是成功的,但构建模型的过程非常坎坷,因为我花了很多时间学习我不了解的概念。在本文中,我想回顾并记录我想在构建模型之前能了解的内容。如果你想了解更多数据分析相关内容,可以阅读以下这些文章:
Machine Learning知识点:机器学习里的聚类分析技巧
三个月如何搞定机器学习的数学原理?
研究了2000+笔记本,我们总结了最适合机器学习、数据科学和深度学习的电脑
评估机器学习算法的指标
在构建你的模型前,你需要了解以下4个概念:
1. 用简单的网页用户界面部署模型
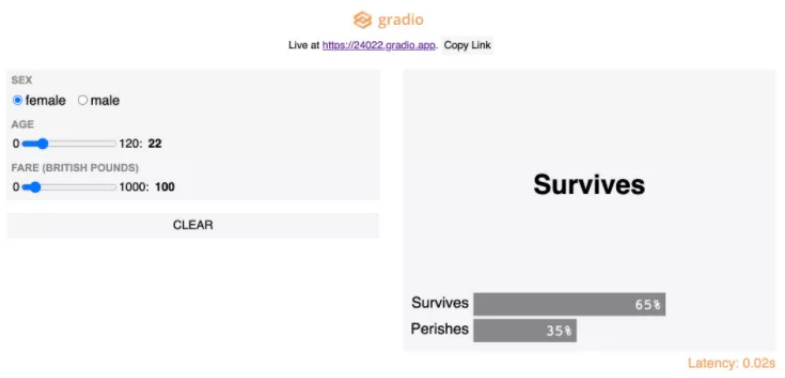
我最近经常使用一个Python包-Gradio,只需三行代码就能为机器学习构建并部署网页应用程序。它的用法和Streamlit或Flask一样,但是我发现,Gradio在部署模型方面更快也更易上手。
为什么Gradio更好用?有以下几个原因:
- 1. 可以进行进一步的模型验证。具体来说,你可以用Gradio交互测试模型中的不同的输入。你还可以获得来自不同人群的反馈,包括其他利益相关者、领域专家,尤其是非编程人员。
- 2. 可以很好地进行演示。就我个人而言,我发现向某些利益相关者展示 Jupyter Notebook 对我的模型没有任何加分,尽管模型效果非常好。但使用这样的library可以更易于交流,更好地推销自己。
- 3. 易于实施和推广。重申一下,这是一个很小学习曲线,因为它只需要 3 行代码。同时,它还非常容易推广,因为大家都可以通过公共链接访问这个 Web 应用程序。
结论:利用像 Gradio 这种 ML 模型,能进行更好的测试和交流。
2.特征的重要性
特征重要性是指一组技术,它根据输入变量对目标变量预估的准确度,为输入变量打分。分数越高,特征在模型中越重要。
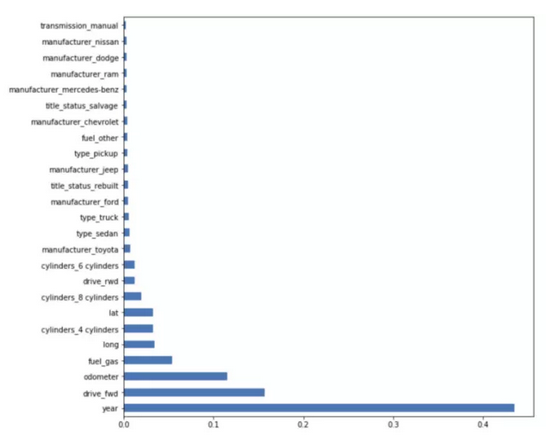
例如,如果我想使用上图中的特征来预估汽车的价格,通过特征重要性分析,我可以确定模型年份、汽车是否为前轮驱动、以及行驶里程数(里程表)在预测汽车价格时是最重要的因素。
非常棒,对吧。我相信你已经逐渐明白Gradio为什么这么好用了。
在特征选择方面,特征重要性非常有用。通过对初步模型进行特征重要性分析,你可以轻松确定哪些特征在模型中更重要,哪些不那么重要。
更重要的是,特征重要性简化了模型说明,以及成果演示这两个过程,因为它会直接显示哪些特征最能说明目标变量。
结论:利用特征重要性来优化特征选择、模型说明及演示交流。
3. 超参数调优
机器学习的本质是找到最适合数据集的模型参数,而这是通过训练模型来实现的。
另一方面,超参数不能直接从模型训练过程中学习到。这些是模型中更高级的概念,在训练模型之前通常是固定的。
超参数的例子有:
- 学习率
- 一棵树的叶子数或最大深度
- 神经网络中隐藏层的数量
超参数虽然不是由数据本身决定的,但设置正确的超参数可以将机器学习模型的准确率从 80% 提高到 95% 以上。我在实际操作中就是这样。
我认为,可以通过使用一些技术,自动优化模型的超参数,这样就不必测试一堆不同的数据了。
两种最常用的技术,是网格搜索和随机搜索。
结论:使用网格搜索和随机搜索等技术可以优化模型的超参数,大幅提高模型性能。
4. 模型评估指标
这可能是在线课程、训练营或在线资源中,最容易被忽视的领域之一。 然而,它可以说是数据科学中最重要的概念之一。
如果你想要了解机器学习模型评估的指标,那么你需要深入了解待解决的业务问题。
如上图所示,最初几周我没有取得太大进展,因为我没有清楚地了解业务问题,因此,我不知道我应该通过哪个指标优化我的模型。
因此,我们可以将这个问题分解为两个步骤:
- 1. 了解业务问题的需求
了解业务要解决的问题是什么、问题的参数是什么、可用的数据有哪些、利益相关者有哪些,以及模型将如何集成到业务流程/产品中。
- 2. 选择正确的指标来评估模型
在我的项目中,我们对比了将指标分为假阳性和假阴性的结果。我们的最终决策主要取决于该模型将如何集成到业务流程中。
结论:了解业务问题。深入了解所有相关指标,并了解选择每个指标的结果。
如果有不太清楚的概念,我强烈建议你花一些时间掌握它们。总的来说,这四个概念使我:
- 将模型的准确度从85%左右提高至95%左右。
- 使模型说明和成果演示变得更简单,尤其是对那些不那么精通技术的人。
- 从利益相关者那里获得更多反馈。
谢谢阅读!你还可以订阅我们的YouTube频道,观看大量数据科学相关公开课:https://www.youtube.com/channel/UCa8NLpvi70mHVsW4J_x9OeQ;在LinkedIn上关注我们,扩展你的人际网络!https://www.linkedin.com/company/dataapplab/
原文作者:Terence Shin
翻译作者:Lia
美工编辑:过儿
校对审稿:Jiawei Tong
原文链接:https://towardsdatascience.com/4-machine-learning-concepts-i-wish-i-knew-when-i-built-my-first-model-3b8ca9506451





