
这六个SQL小技巧,让你的分析效率突飞猛进!
数据科学家/分析师应该了解 SQL,事实上,所有从事数据和分析工作的专业人员都应该了解 SQL。在某种程度上,SQL 是一项被低估的数据科学技能,因为很多人认为它是一种从数据库中提取数据,以供Pandas和{tidyverse}这两个更花哨的方式来整理数据,虽然很有必要,但却不一点都不流行。

然而,随着该行业每天都在收集和生产大量数据,只要数据位于符合 SQL 标准的数据库中,SQL 仍然是帮助你调查、过滤和聚合数据来彻底了解业务的最有效工具。通过使用 SQL 对数据进行交叉分析,分析人员可以识别值得进一步研究的模式,通常会重新定义分析人群和变量,使其大大小于初始范围。
因此,与其将庞大的数据集传输到 Python 或 R 中,分析的第一步应该是使用 SQL ,从我们的数据中获取信息见解。
在现实世界的关系数据库中,SQL 不仅仅是 SELECT、JOIN、ORDER BY 语句。在这篇文章中,我将讨论 6 个技巧(和一个额外技巧),使你的分析更高效地使用 SQL 及其与其他编程语言(如 Python 和 R)的集成。
在本次实际操作中,我们将使用 Oracle SQL 来处理下面的玩具数据表,该表由多种类型的数据元素组成,如果你想了解更多数据分析相关内容,可以阅读以下这些文章:
Facebook和Microsoft数据科学家面试,他们会问这些SQL问题
如何在Jupyter Notebook里运行SQL?
面试常见5大SQL题目:培养SQL技能,助你完胜任何面试!
四条SQL准则:提升你的数据科学技能
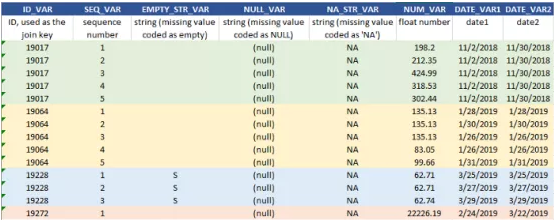
1. 用COALESCE() 处理 NULL/缺失数据
处理缺失值时,COALESCE() 函数是我们的独家秘诀,在这种情况下,它将 NULL 重新编写为第二个参数中指定的值。在本实例中,我们可以将 NULL_VAR 重新编为字符值“MISSING”
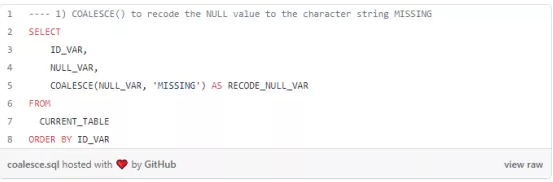
此代码片段会返回
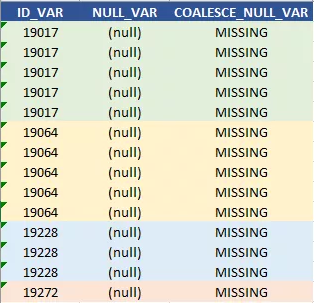
然而,有一点需要注意,在数据库中,除了 NULL 之外,还可以通过多种方式对缺失值进行处理。例如,它们可以是空字符串/空格(例如,表中的 EMPTY_STR_VAR),或字符串“NA”(例如,表中的 NA_STR_VAR)。在这些情况下, COALESCE( ) 就不能用了,但可以使用 CASE WHEN 语句进行处理,
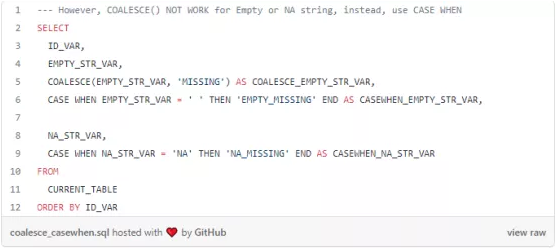
用CASE WHEN 重新编写空格或NA

2. 计算运行总次数和累计次数
当我们对总数(而不是单个值)感兴趣,从而进行潜在的分析、群体细分和异常值识别时,运行总次数可能很有用。
下面展示了如何计算变量 NUM_VAR 的运行总数和累积频率
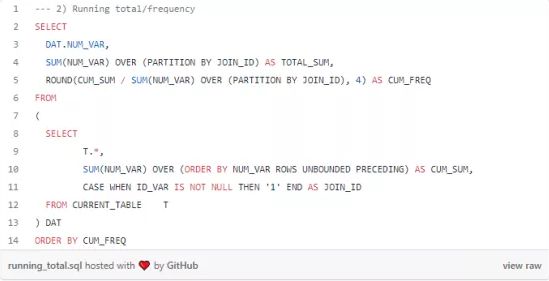
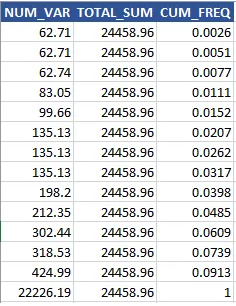
这是我们的输出结果。
这里有两个技巧,(1) 对无边界的行进行求和,可以计算出所有先前值的总和;(2)创建JOIN_ID,计算总和。
我们使用窗口函数进行此计算,从累积频率来看不难发现,最后一条记录为异常值。
3. 找到没有self join的极端值的记录
这里,我们的任务是为每个独有 ID 返回具有最大 NUM_VAR 值的行。直观的查询首先是使用 group by 找到每个 ID 的最大值,然后对 ID 和最大值进行self join。但以下是更简单的方法:

此查询应为我们提供以下输出结果,显示按 ID 分组的具有最大 NUM_VAR 值的行

4. 条件 WHERE 从句
每个人都知道 SQL 中的 WHERE 从句。事实上,我发现自己使用条件 WHERE 从句的次数更加频繁。例如,对于玩具表,我们只想保留满足以下逻辑的行,
— if SEQ_VAR in (1, 2, 3) & diff(DATE_VAR2, DATE_VAR1)≥ 0
— elif SEQ_VAR in (4, 5, 6) & diff(DATE_VAR2, DATE_VAR1) ≥1
— else diff(DATE_VAR2,DATE_VAR1)≥2
现在条件 WHERE 从句派上用场了,

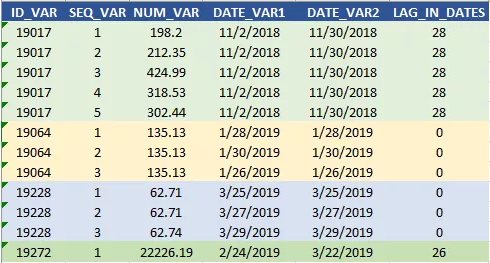
上述逻辑应该消除ID = 19064的序列4、5,因为date2和date1之间的差值为 0,这正是上面查询返回的内容。
5. Lag() 和 Lead() 来处理连续行
Lag(查看前一行)和 Lead(查看下一行)可能是我日常工作中最常用的两个分析函数。简而言之,用户通过这两个函数一次查询多个行,而无需自连接。
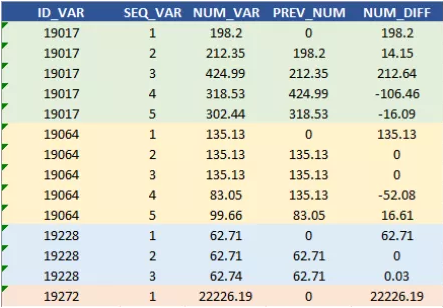
假设,我们要计算两个连续行(按序列排序)之间的 NUM_VAR 差异:
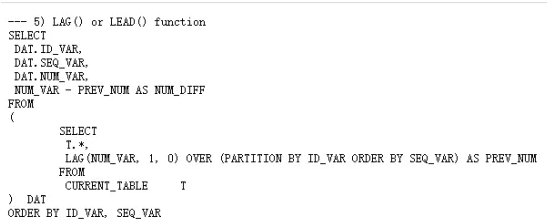
LAG() 函数会返回前一行,如果没有(即每个 ID 的第一行),则 PREV_NUM 编码为 0 ,计算如下 NUM_DIFF所示的差值,
6. 将SQL查询集成到Python和R语言
将 SQL 查询集成到 Python 和 R 语言中的前提,是通过 ODBC 或 JDBC 建立数据库连接。由于这超出了本文的范围,我不会在这里详细讨论它。
现在,我们先假设已经将 Python 和 R 语言连接到了我们的数据库,在 Python 中使用查询的最直接方法,是将其作为字符串复制粘贴,然后调用 pandas.read_sql(),

只要我们的查询很短,并且无需进一步更改,就可以证明这种方法很有用。但是,如果我们的查询有 1000 行,或者我们需要不断更改呢?在这样的情形下,我们希望将 .sql 文件直接读入 Python 或 R语言中。下面将演示如何在 Python 中操作 getSQL 函数,其思路同样适用于R语言,
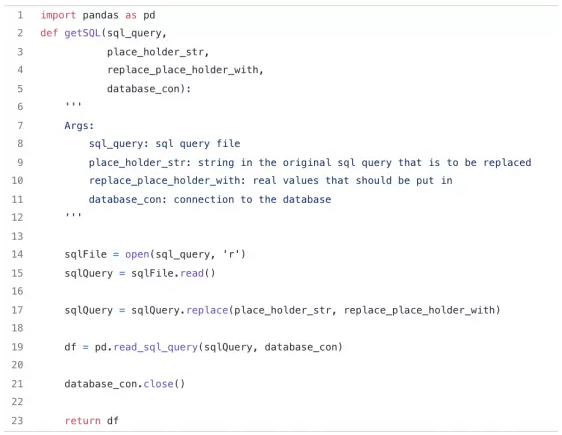
这里,第一个 arg sql_query 接受一个独立的 .sql 文件,这个文件就能更易于维护:
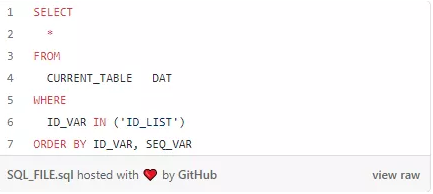
“ID_LIST”是我们将要放入的值的占位符字符串,可以使用以下代码调用 getSQL(),

额外提示,SQL 中的正则表达式
尽管在 SQL 中,我并不常用正则表达式,但它有时可以便于文本提取。例如,以下代码显示了如何使用 REGEXP_INSTR( ) 来查找和提取数字。

希望这篇文章对你有所帮助!你还可以订阅我们的YouTube频道,观看大量数据科学相关公开课:https://www.youtube.com/channel/UCa8NLpvi70mHVsW4J_x9OeQ;在LinkedIn上关注我们,扩展你的人际网络!https://www.linkedin.com/company/dataapplab/
原文作者:Yi Li
翻译作者:Lia
美工编辑:过儿
校对审稿:Jiawei Tong
原文链接:https://towardsdatascience.com/6-sql-tricks-every-data-scientist-should-know-f84be499aea5





