
如何在Jupyter Notebook里运行SQL?
现在的我们要面对的一个现实就是—–数据库是无处不在的。虽然在学习数据科学的过程中,你一般只会处理CSV文件,但现实对你的要求不止于此,大多数公司还希望你能把数据存储到数据库当中。
在今天的文章中,我想快速概括一下如何把Jupyter notebook/JupyterLab用作SQL IDE的方法。此前,我有用过各种Python libraries去连接数据库,而这个小技巧能节省你的大量时间和输入量。
读完本文,你不但可以在Notebook上直接执行SQL查询/过程操作,还可以将任意的查询结果存储到一个变量中,供以后的分析使用。如果你想了解更多数据分析相关内容,可以阅读以下这些文章:
面试常见5大SQL题目:培养SQL技能,助你完胜任何面试!
四条SQL准则:提升你的数据科学技能
用Python进行探索性数据分析(EDA)实例——扒了200多天的2万条聊天记录,我发现了群聊的秘密
如何在Pandas里写SQL查询语句?
那么简介就到这里,让我们赶快进入主题吧。
初始设置
首先,你需要安装一个library,能让你直接在Notebook上运行SQL。所以,粘贴以下内容到Jupyter单元格中:
!pip install ipython-sql写这篇文章时,我正在处理一个Oracle的数据库。如果你也是这个情况,就需要确认自己安装了cx_Oracle。如果没有,可以快速从网上找到一个你要用的library。我认为以下几种很好:
- pyodbc—用于SQL Server
- mysql—用于MySQL
- psycopg2—用于 PostgreSQL
现在,我们要用sqlalchemy 这个library创建一个连接到数据库的引擎。每个连接的字符串只需使用一次——也就是说,你不用每次建立连接时都重复一遍。
下面,是一些适用于各种数据库的通用连接字符串:
- PostgreSQL: postgresql://scott:tiger@localhost/mydatabase
- MySQL: mysql://scott:tiger@localhost/foo
- Oracle: oracle://scott:tiger@127.0.0.1:1521/sidname
- SQL Server: mssql+pyodbc://scott:tiger@mydsn
- SQLite: sqlite:///foo.db
下面是一个Oracle DB的例子:
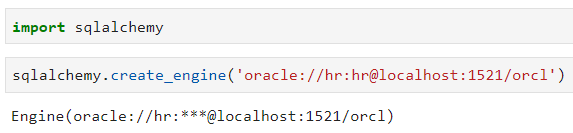
现在,我们就能加载之前安装的SQL模块了:

然后,使用前面的连接字符串连接到数据库。要注意,列的内容是以%作为前缀的:
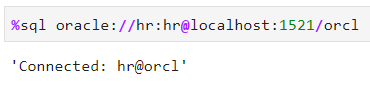
如果你的输出和我一样,那就表示一切正常,你就可以继续啦!
开始操作
好的,现在你已经准备就绪了。首先,我会教你如何把多行SQL查询传输到Juypter单元格中。因为如果没有这个魔法命令,你还得导入各种libraries、连接到数据库、用括号括起查询,然后再执行。但现在,你只需要在代码前加上 %%sql 或 %sql 前缀,我在下面进行了演示。
将整个单元格标记为 SQL 模块
让我们从这一步先开始,因为它允许你输入多行SQL语句。唯一的要求就是,要在开始前添加%% sql的前缀。下面,我从表格中选择了前五行:

没错,就是这么简单!如果你执行这个单元格,会得到以下输出:
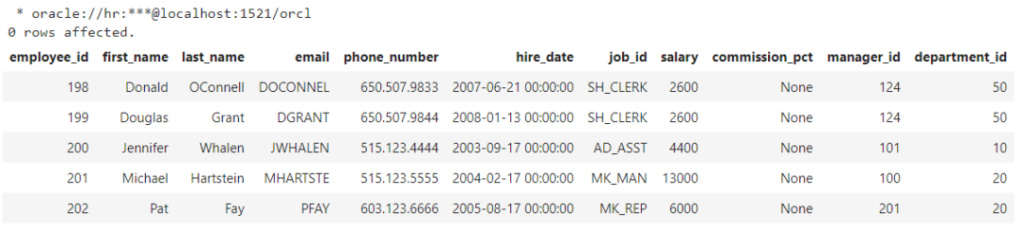
虽然看起来有点像一个Pandas的数据框,但实际上不是,它只展示了这个表格的外观。
单行语句- 把结果存储到变量中
当然,除了多行语句,你还可以将SQL查询的结果存储到一个变量中。这里只有一个百分号:%sql。
让我们看看实际的操作情况——先从 phone_number 列中选择一个值:
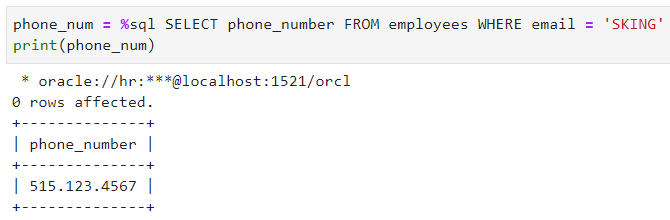
可以看到,如果我print它,输出值并不是你想要的,那该怎么解决?以下是解决方法:
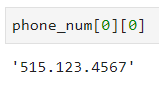
不用担心,只是一个简单的索引的问题。
你还能做什么?
你可能想知道,除此之外,ippython -sql还能为我们提供什么功能?有很多!接下来,我要分享的这两个功能可能不是很特别,但都会有所帮助。话不多说,我们开始吧。
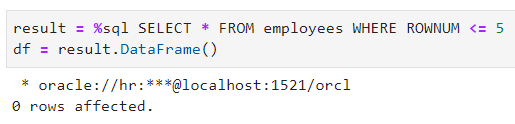
转换成 Pandas DataFrame
这是ipython-sql 中一个不错的附加功能,它可以帮你节省一些时间,而且你也不必进行手动转换了。下面是从数据库中选择的一些数据集,我准备调用 .DataFrame() 的方法进行操作:
现在,我们可以同时检查数据框和它的类型,来验证内容是否都和我们的预期相同:
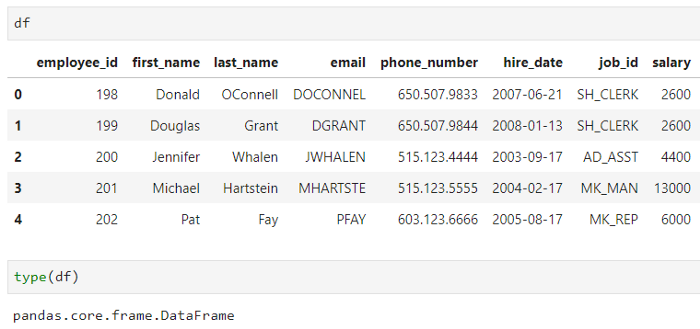
数据看起来不错,格式也不错,好的,我们可以继续了。
绘图
假设你很着急,想快速从数据库中获取一些数据,并制作条形图。处于展示目的,我会导入 matplotlib 并放大所有内容,然后把一些 SQL 查询的结果存储到一个变量中。
操作完成后,你可以调用.bar()的方法来制作一个条形图:
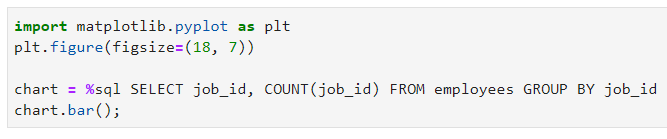
相对应的图是这样的:
只用一行代码就能绘图是非常方便的。另外请注意,你还可以使用.pie()来画饼图—你还可以找找其他选项。
总结
虽然我不认为本文中的任何内容有多厉害,但我也希望你能欣赏这种操作模式上的简洁性。
如果你只需要执行查询,并且不需要任何更高级的内容,那这也能作为标准SQL IDE的替代方案。
无论如何,希望你能从这篇文章中获益。感谢你的阅读。你还可以订阅我们的YouTube频道,观看大量数据科学相关公开课:https://www.youtube.com/channel/UCa8NLpvi70mHVsW4J_x9OeQ;在LinkedIn上关注我们,扩展你的人际网络!https://www.linkedin.com/company/dataapplab/
原文作者:Dario Radečić
翻译作者:Lea
美工编辑:过儿
校对审稿:Jiawei Tong
原文链接:https://towardsdatascience.com/heres-how-to-run-sql-in-jupyter-notebooks-f26eb90f3259





