
Pandas2.0的速度提高了32倍!
当你将数据存储在PyArrow而不是NumPy中时,Pandas 2.0会快很多。Pandas2.0有什么新内容?如果你想了解更多关于Pandas的相关内容,可以阅读以下这些文章:
Pandas的秘密:5个鲜为人知的功能,将彻底改变你的数据分析技能
只会Pandas?来学习这25种Pandas变SQL的方法,让你的数据分析更得心应手!
快速上手Pandas数据结构合并
Pandas和SQL,数据科学家应该用哪个?
Pandas是一个用于处理数据的Python库,在Python开发者中非常流行。如果你不熟悉它,你可以把它想象成一个程序化电子表格。
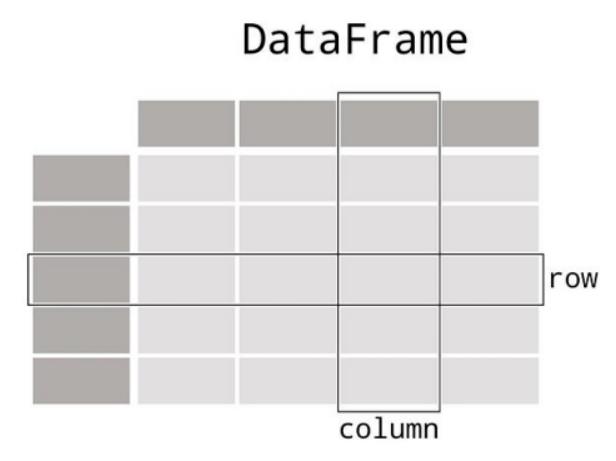
使用Pandas你可以操作行和列、计算统计数据、连接表、透视表、转换为其他表以及执行更多操作。
由于该库非常强大,因此它已成为许多数据科学和机器学习系统的基础。
Pandas2.0有什么新内容?
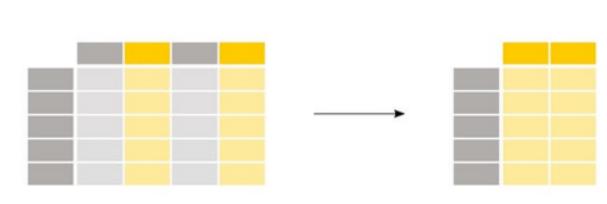
根据发行说明,这里是我们在Pandas 2.0中看到的重要改进的完整列表:
- 使用pip附加功能安装可选依赖项
- 索引现在可以容纳numpy的数字类型了
- 配置选项,mode.dtype_backend,用于返回pyarrow支持的dtype
- 写入时复制的改进
该版本还将附带此处描述的许多其他改进和错误修复。但它有什么特别之处呢?
新版本附带了一项重要的改进,该改进经过了很长时间的开发,以提供更好的性能和数据处理。
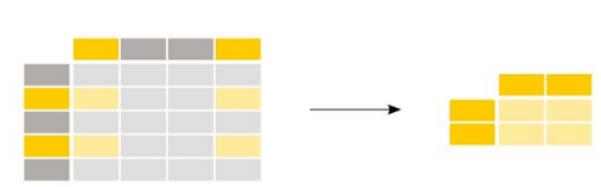
到目前为止,Pandas依靠NumPy来保存表格数据,例如字符串,数字,但也包括更复杂的数据。但是,NumPy有其局限性,从Marc Garcia的文章中我们可以了解到它不支持本机字符串和缺失值。因此,对于缺少的数字,应使用特殊编号或 NaN。
这意味着对于每种数据类型,缺失值实现都是复杂且棘手的处理。
因此,Panda 2.0将允许你在PyArrow中处理数据。
PyArrow更适合表格数据,可以轻松存储字符串,最重要的是,也使空值处理更容易。
因为现在,在内部,数据数组旁边会有第二个数组,指示值是否存在。使空值的处理更加直接。
正如Marc所提到的,PyArrow的引入在性能方面也很有意义。他举了一个例子,其中250万行的字符串系列的endwith在装有PyArrow的笔记本电脑上比NumPy 快 31.6倍。因此,我写出了标题中的数字。
PyArrow不是在Python中实现的,而是在C++中实现的,以获得良好的性能提升。我知道有些开发人员不太认为Python是更快编程语言的代理。
但这并不是一个缺点。首先,能够用Python编写,同时从其他专门用于性能的语言中获得收益,这是Python的特别之处。
其次,在这里,我将自我宣称自己是所有使用Python的人的代表。
其实引擎盖下是什么并不重要,只要你坐在兰博基尼里就可以了。
要享受PyArrow,你必须在代码库中切换到它,当然,一旦可用,请安装候选版本或正式版本。
只有1%的人把这么长的文章读到最后。祝贺你!和你谈谈编码一定很愉快。你还可以订阅我们的YouTube频道,观看大量大数据行业相关公开课:https://www.youtube.com/channel/UCa8NLpvi70mHVsW4J_x9OeQ;在LinkedIn上关注我们,扩展你的人际网络!https://www.linkedin.com/company/dataapplab/
原文作者:Tom Smykowski
翻译作者:马薏菲
美工编辑:过儿
校对审稿:Chuang
原文链接:https://tomaszs2.medium.com/pandas-2-0-up-to-32x-faster-57bbf03f002a





