
Hadoop是什么?一篇文章带你快速入门
什么是 Apache Hadoop?✦
Hadoop是一个开源数据库框架,由Apache软件基金会(ASF)管理,编写语言为Java,用户可以通过Hadoop存储并处理大数据集(从GB到 PB 级)。Hadoop 的设计灵感来自谷歌,是 Apache 最高级别的项目之一。
如果你想了解更多数据分析相关内容,可以阅读以下这些文章:
Spark/Hadoop/MapReduce入门101
DS vs DE:数据科学家与数据工程师的薪资对比
金融中的数据分析师,都做什么工作?
为什么BI 对数据科学家很重要?
Hadoop 发展史✦
Hadoop 最初由 Doug Cutting 和 Mike Cafarella 创立,当时,他们都在从事 Apache Nutch 项目。这个项目目的是建立一个可以索引10亿页的搜索引擎系统。根据相关研究,他们得出结论——这样的硬件系统将花费大约 50 万美元,每月要支出大约 30,000 美元的运行成本,可以说是巨资级别的项目了。所以,他们开始寻找合理的解决方案,从而降低运行成本,同时解决存储、并处理大型数据集的问题。
2003 年,Google发表了一篇有关分布式文件系统的论文,即谷歌文件系统(Goolge File System – GFS),用于存储大型的数据集。该论文指导他们解决由于网络爬行和索引过程而导致的海量文件存储问题。2004 年,Google 发表了另一篇有关MapReduce 技术的论文,这个技术解决了处理这些大型数据集的第二个问题。最终,GFS 和 MapReduce 解决了Apache Nutch项目中的问题。两人开始将Google的开源技术运用至自己的项目中,因为他们知道开源是让技术惠及更多用户的好方法。
2005 年,Cutting 意识到项目背后只有两个工程师是远远不够的,于是他开始与Yahoo合作,Yahoo拥有一支庞大的工程团队,而且热衷于 Apache Nutch 项目。Cutting还发现,只有保证在更大的集群中稳定运行项目 ,Nutch才能充分发挥其潜力,而此时,集群的节点数量仍被限制在20-40个。Cutting开发了一个名为 Hadoop 的新项目,该项目以Cutting 儿子的玩具大象Hadoop命名,因此Hadoop象征黄色玩具大象。
2007 年,Yahoo成功使用Hadoop在1000个节点集群上进行了测试,并投入使用。后来,Yahoo将 Hadoop 作为开源项目发布给了 Apache 软件基金会;2008 年,ASF 成功使用 Hadoop 在4000 个节点集群进行测试。2009 年,Hadoop在不到17个小时的时间内通过了对PB (PetaByte)数据的排序测试。2011 年,ASF 发布了 Apache Hadoop 1.0,并于 2017 年 12 月发布了最新版本 Apache Hadoop 3.0。
Hadoop解决了哪些问题?✦
想象一下你的日常活动、拍摄照片和视频、查看电子邮件、使用智能手机应用程序、查看社交媒体帐户、购物,所有这些都是存储在数据库中的数据。数据可以对各种事件和趋势产生巨大影响。
如今,数据的产生速度越来越快。想象一下您在社交媒体上的日常活动,社交媒体是大数据的最大贡献者,可以提供有关人们行为的信息,每分钟都存储为数据,并累积成更大的数据。大数据(Big Data)是指需要存储、分析、处理的海量数据。这就是 Hadoop 渗入日常,并展示其影响力的地方。
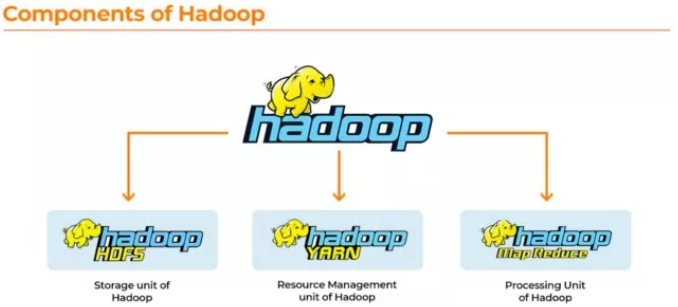
Hadoop的开发是为了解决大数据的两个主要问题——存储海量数据并处理存储的数据。Hadoop 的两个主要组成部分是 Hadoop 分布式文件系统 (HDFS),和MapReduce 技术,前者存储海量数据,后者是处理数据时用到的技术。
Hadoop 的组成部分及其大数据解决方案:
1. HDFS:HDFS是一个专用文件系统,用于通过流访问模式,用普通、廉价硬件集群来存储大数据。该系统便于将数据存储在集群中的多个节点上,从而保证了数据的安全性和容错性。Hadoop 将每个数据集的三个副本存储在三个不同的位置,确保 Hadoop 不会出现单点故障。
2. MapReduce:为了处理存储在 HDFS 中的数据,一个查询会被发出,用来处理 HDFS 中的数据集。Mapping出现在 Hadoop 检测数据的存储位置,并将查询分解为多个部分,以同时处理数据。这种方法称为并行执行(Parallel Execution)。将多个部分的结果连接起来,然后将整体的结果发回给用户,这称为reduce过程。
3. YARN:Yet Another Resource Negotiator(YARN)被用于管理集群的资源,同时也是 Hadoop 中协调应用程序运行时的作业调度框架。通过 YARN 管理 Hadoop 的资源,Hadoop可以更好地运行大数据。
与将数据存储在本地机器中等传统方法相比,Hadoop 简化了数据存储、处理和分析。无数设备在产生大量无法用传统方式存储、处理和分析的数据。随着数据量的增加,由于存储空间不够,计算机存储大数据的能力下降。
另一种情况,是将数据存储在远程服务器上,即Enterprise Approach。为了处理这些数据,必须从服务器获取,然后再处理数据。想象一下,如果想要获取 500 GB的数据,不但非常麻烦,还会非常昂贵。因此,数据的区域性是 Hadoop 最具吸引力和最可靠的特性之一。
Apache Hadoop Vs. Apache Spark

Spark 是 Apache 的一个较新的项目,于 2012 年在加州大学伯克利分校的 AMPLab 开发。Spark也是开源的大数据集数据处理引擎。Spark 更像是 MapReduce 的 Hadoop 升级版。与Hadoop类似,Spark将大型任务分配到不同的节点上。
Spark是一个顶级 Apache 项目,专注于跨集群并行处理数据,但主要区别在于, Spark 会访问随机存取存储器 (RAM),而 MapReduce 是在磁盘上处理数据的。数据较少时,Spark 的处理速度比 MapReduce 快 100 倍。但是,在处理大量数据时,Spark的处理速度最多只能快 3 倍。
Hadoop 的维护成本较低,因为它主要取决于处理数据是磁盘的存储类型。而 Spark 的成本要高得多,因为它取决于实时数据处理的内存计算。因此,Spark需要包含大量 RAM 的旋转节点。
尽管这两个平台在处理数据方面相似,但优势各不相同。Hadoop适用于批量处理和线性数据处理;而Spark 更适合自发处理,以及处理实时的、非结构化的数据流。
当数据量呈指数增长时,Hadoop 通过 HDFS 进行扩展,并适应数据节点。Spark 也需要依赖 HDFS 处理大量数据。
Sparks 的安全性体现在,它通过两种方式进行身份验证,即事件日志记录(logging)或共享秘密(shared secret)。另一方面,Hadoop 安全更高,因为Hadoop使用多重身份验证,从而增强了安全性,并通过各种方法请求访问。但是 Spark 能够使用 Hadoop 的安全功能扩展其安全级别。
在机器学习(Machine Learning)方面,Spark 表现更出色,因为它可以运行 MLlib,并执行内存迭代式机器学习计算。Spark还包含一些工具,这些工具可用于构建管道、执行回归、分类和评估等。
本文带你了解了Hadoop, 并扩展讨论了Spark的技术和应用场景。希望本文对你有所帮助。感谢你的阅读!你还可以订阅我们的YouTube频道,观看大量数据科学相关公开课:https://www.youtube.com/channel/UCa8NLpvi70mHVsW4J_x9OeQ;在LinkedIn上关注我们,扩展你的人际网络!https://www.linkedin.com/company/dataapplab/
原文作者:Hatice K. Erdogan
翻译作者:Lia
美工编辑:过儿
校对审稿:Jiawei Tong
原文链接:https://towardsdev.com/a-beginners-guide-to-hadoop-c698a2cc601b




