
RAG与Fine Tuning:如何选择正确的方法
生成式人工智能有潜力改变你的业务和数据工程团队,但前提是要正确实施。那么,你的数据团队如何才能真正利用大型语言模型或生成式人工智能(GenAI)计划来驱动价值呢?
领先的组织通常在两种新兴框架之间做出选择,这些框架区分了其业务价值的人工智能:RAG与Fine Tuning。
什么是检索增强生成(RAG)与Fine Tuning之间的区别?你的组织应该什么时候选择RAG还是Fine Tuning?应该同时使用吗?
我们将深入探讨RAG与Fine Tuning的基础知识,了解每种方法的最佳用途,它们的优点以及一些实际应用案例来帮助你入门。如果你想了解更多相关技术类的相关内容,可以阅读以下这些文章:
如何为你的业务选择合适的大型语言模型(LLM)
如何使用Code Llama构建自己的LLM编码助手
LLMs能否取代数据分析师?
LeMA:对于一个LLM来说,学习数学就是在犯错!
目录
- 什么是检索增强生成(RAG)?
- 什么是Fine Tuning?
- 什么时候使用检索增强生成(RAG)?
- 检索增强生成使用案例
- 什么时候使用Fine Tuning?
- Fine Tuning使用案例
- 如何在RAG与Fine Tuning之间做出选择
常见问题解答
- RAG比Fine Tuning好吗?
- RAG与Fine Tuning和提示工程有什么区别?
- RAG和Fine Tuning可以一起使用吗?
- RAG比Fine Tuning便宜吗?
- RAG与模型Fine Tuning有什么区别?
什么是检索增强生成(RAG)?
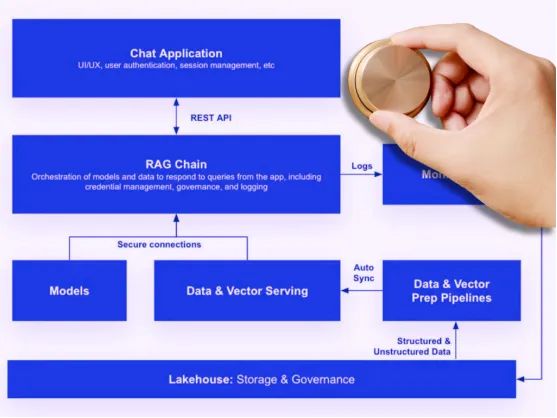
检索增强生成(RAG)是Meta于2020年推出的一种架构框架,将你的大型语言模型(LLM)连接到一个精选的、动态的数据库。这通过允许LLM访问和结合最新的、可靠的信息来改进其输出和推理能力。
RAG开发是一个复杂的过程,并非凭空而来。它可以涉及提示工程、像Pinecone这样的向量数据库、嵌入向量和语义层、数据建模、数据编排和数据管道——所有这些都为RAG量身定制。
以下是RAG流程的工作方式:
- 查询处理:当用户向系统提交查询时,流程开始。这是RAG链检索机制的起点。
- 数据检索:根据查询,RAG系统搜索数据库以找到相关数据。这一步涉及复杂的算法,将查询与数据库中最适当和上下文相关的信息进行匹配。
- 与LLM集成:一旦检索到相关数据,它就会与用户的初始查询相结合并输入LLM。
- 响应生成:利用LLM的能力和检索数据提供的上下文,系统生成一个不仅准确而且针对查询特定上下文的响应。
因此,开发RAG架构对你的数据团队来说是一个复杂的任务,需要开发数据管道来提供增强LLM的专有上下文数据。但是,如果做得正确,RAG可以为AI驱动的数据产品增加巨大的价值。
什么是Fine Tuning?
Fine Tuning是一种生成式人工智能开发的另一种,涉及在较小的、专门的、有标签的数据集上训练LLM,并根据新数据调整模型的参数和嵌入。
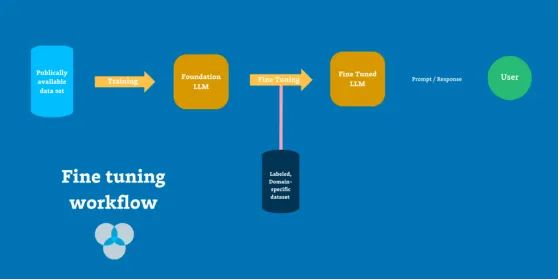
在企业级AI的背景下,RAG和Fine Tuning的最终目标是相同的:从AI模型中驱动更大的商业价值。但与其通过访问专有数据库来增强现有LLM,不如通过为特定领域定制模型本身来进行更深入的Fine Tuning。
Fine Tuning涉及在较小的、专门的、有标签的数据集上训练LLM,并根据新数据调整模型的参数和嵌入。通过使模型与特定领域的细微差别和术语对齐,Fine Tuning帮助模型在特定任务中表现得更好。
什么时候使用检索增强生成(RAG)?
对于大多数企业用例,RAG比Fine Tuning更适合,因为它更安全、更可扩展且更可靠。
RAG允许增强的安全性和数据隐私
使用RAG,你的专有数据保留在安全的数据库环境中,允许严格的访问控制;而Fine Tuning中,数据成为模型训练集的一部分,可能会在没有相应可见性的情况下暴露给更广泛的访问。
RAG具有成本效益和可扩展性
Fine Tuning大型AI模型资源密集,需耗费大量时间和计算能力。通过将第一方数据整合到响应中而不是模型参数中,RAG能够在计算级别限制资源成本,并消除训练阶段,以及通过避免花费数周或数月时间制作和标记训练集而在人力级别上节省成本。
RAG提供可靠的结果
AI的价值在于其提供准确响应的能力。RAG在这方面表现出色,因为它不断从最新的精选数据集中提取信息来指导其输出。而且,如果出现问题,数据团队可以更轻松地追踪响应的来源,从而更清楚地了解输出是如何形成的,以及数据出错的地方。
检索增强生成使用案例
2024年初,Apache Airflow和Superset的创建者、Preset的创始人兼首席执行官Maxime Beauchemin告诉我们他的团队如何使用RAG为Preset的BI工具带来AI驱动的功能。
最初,Max和他的团队探索使用OpenAI的API来实现AI驱动的功能,例如客户使用普通语言文本生成SQL查询。但是,鉴于ChatGPT上下文窗口的限制,无法向AI提供关于其数据集的所有必要信息(例如表格、命名约定、列名和数据类型)。而当他们尝试Fine Tuning模型和自定义训练时,发现基础设施尚未完全就绪,特别是当他们还需要为每个客户进行细分时。
Max表示:“我迫不及待地想要拥有能够使用你组织的私人信息、GitHub、Wiki、dbt项目、Airflow DAG、数据库架构进行自定义训练或Fine Tuning的基础设施。但我们与许多其他创始人和在这个问题上工作的人进行了交谈,我很清楚在这个时代自定义训练和Fine Tuning真的很困难。”
鉴于Max和他的团队无法将客户的整个数据库甚至只是元数据放入上下文窗口中,“我们意识到我们需要非常聪明的使用RAG,即检索正确的信息以生成正确的SQL。目前,这一切都关乎为正确的问题检索正确的信息,”他说。
什么时候使用Fine Tuning?
根据可用资源,一些组织可能会选择Fine Tuning作为从其生成式AI计划中驱动价值的替代方案。
通过使模型与特定领域的细微差别和术语对齐,Fine Tuning帮助模型在特定任务中表现得更好。它在领域特定的情况下非常有效,比如以特定语气或风格回应详细的提示,例如法律简报或客户支持票据。它也是克服信息偏差和其他限制(如语言重复或不一致)的绝佳选择。
与RAG一样,Fine Tuning需要建立有效的数据管道,首先将专有数据提供给Fine Tuning过程。
Fine Tuning使用案例
过去一年的几项研究表明,Fine Tuning模型显著优于现成的GPT-3和其他公开可用的模型。
已经确定,对于许多用例,Fine Tuning的小模型可以优于大型通用模型——在某些情况下,使Fine Tuning成为一种可行的成本效益路径。
例如,Snorkel AI创建了一个数据中心基础模型,以弥合其基础模型和企业AI之间的差距。他们的Snorkel Flow功能包括Fine Tuning、提示构建器和“暖启动”,为数据科学和机器学习团队提供所需的工具,以有效地将基础模型用于性能关键的企业用例。
这导致Snorkel Flow和数据中心基础模型开发实现了与Fine Tuning的GPT-3模型相同的质量,部署模型小了1400倍,需要的真值(GT)标签不到1%,生产运行成本仅为0.1%。
如何在RAG与Fine Tuning之间做出选择
你应该根据用例和可用资源在RAG与Fine Tuning之间做出选择。虽然RAG是大多数用例的首选,但这并不意味着RAG和Fine Tuning是互斥的。虽然Fine Tuning并不总是最实用的解决方案——训练LLM需要大量的时间、计算和标记——但RAG也很复杂。
如果你有资源,那么同时利用两者肯定是有益的——训练你的模型从最有针对性的上下文数据集中提取最相关的数据。首先考虑你的具体需求,并做出对你的利益相关者驱动最大价值的决定。
无论你使用哪种方法,无论你使用哪一种,人工智能应用程序开发都需要数据管道,通过一些数据存储向这些模型提供公司数据。为了使你的AI正常工作,你需要关注模型依赖的数据管道的质量和可靠性。
RAG或Fine Tuning唯一能成功的方式是你能信任数据。为了实现这一点,团队需要利用数据可观察性——一种可扩展的自动化解决方案,以确保数据的可靠性,识别根本原因,并在影响服务的LLM之前快速解决问题。
感谢阅读!你还可以订阅我们的YouTube频道,观看大量大数据行业相关公开课:https://www.youtube.com/channel/UCa8NLpvi70mHVsW4J_x9OeQ;在LinkedIn上关注我们,扩展你的人际网络!https://www.linkedin.com/company/dataapplab/。
原文作者:Lindsay MacDonald
翻译作者:文杰
美工编辑:过儿
校对审稿:Jason
原文链接:https://www.montecarlodata.com/blog-rag-vs-fine-tuning/#:~:text=Yes%2C%20RAG%20and%20fine%2Dtuning,and%20reliability%20of%20the%20model




