
LLM代理——直观详尽的解释
本文聚焦于“代理”,这是一个允许语言模型进行推理并与世界互动的通用概念。首先,我们将讨论代理是什么以及它们为什么重要,然后我们将看看几种形式的代理,以建立对它们如何工作的直观理解,接着我们将在实际情境中通过实现两个代理来探索它们,一个使用LangChain,另一个从头开始使用Python。
读完本文后,你将了解代理如何帮助语言模型执行复杂任务,并了解如何自己构建代理。如果你想了解更多关于LLM的相关内容,可以阅读以下这些文章:
如何为你的业务选择合适的大型语言模型(LLM)
如何使用Code Llama构建自己的LLM编码助手
LLMs能否取代数据分析师?
LeMA:对于一个LLM来说,学习数学就是在犯错!
这对谁有用?任何对构建最前沿语言建模系统所需工具感兴趣的人。
这篇文章的难度如何?这篇文章概念上简单,但包含了去年的前沿研究,使其对各个经验水平的数据科学家都有相关性。
先决条件:没有,但对语言模型(如OpenAI的GPT)有一些基本了解可能会有所帮助。如果你对某个特定概念或技术感到困惑,我在文章结尾提供了一些相关材料。
单一提示的限制
随着人们探索模型性能和灵活性的极限,语言模型的使用也在不断演变。“上下文学习”,即语言模型从用户提供的示例中学习的特性,是这种探索中产生的一种高级提示策略。

使用ChatGPT进行上下文学习提示的示例。通过指定一些示例作为“上下文”,模型学习如何输出正确的响应。
“检索增强生成”(RAG)是另一种高级提示形式。它是上下文学习的扩展,允许用户将从文档中检索到的信息注入到提示中,从而允许语言模型对以前从未见过的信息进行推断。

RAG的一个简化示例。RAG通常具有高级的检索系统,可以查找与提示相关的信息。然后将该信息注入提示中,这个过程称为“增强”。在这里,我输入了一个RAG提示可能的样子。
这些方法在允许模型引用关键信息或适应高度特定的用例方面非常出色,但它们在一个关键方面受到限制:模型必须在一步中完成所有操作。
想象一下,你要求一个语言模型计算意大利所有地区最古老城市的累计年龄。也就是说,地区1的最古老城市的年龄,地区2的最古老城市的年龄,以此类推,所有这些年龄相加。语言模型必须做很多事情才能回答这样的问题:
- 首先,它必须定义“意大利的地区”是什么。例如,意大利共和国的第一级行政区划,共有20个。
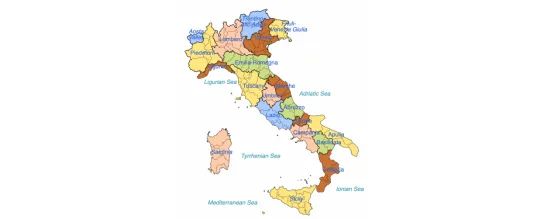
意大利的20个地区,图片来源wikipedia
- 模型必须找到每个地区的最古老城市
- 然后模型必须准确地将这些数字相加以构建最终输出
对于这样的问题,即使是高级提示系统也往往会失败。例如,我们如何期望RAG系统在知道Piedmont是意大利的一个地区之前去获取那里最古老的城市的年龄呢?这个普遍的问题,即需要先处理 X 再处理 Y,正是代理发挥作用的地方。
推理代理
代理的基本思想是允许语言模型将任务分解成步骤,然后逐步执行这些步骤。该领域的第一个重大突破之一是“思维链提示”(在这篇论文中提出https://arxiv.org/abs/2201.11903)。思维链提示是一种上下文学习形式,它使用逻辑推理的示例来教模型如何“思考”问题。
这听起来比实际复杂得多。你只需给模型一个人类如何分解问题的示例,然后要求模型以类似的过程回答问题。

这是使用思维链提示来提高模型算术技能的示例。这类问题即使对于先进的语言模型也存在问题,因为它们往往会对这类问题产生幻觉响应。
这种提示工程方法巧妙而强大,利用模型的本质显著提高其推理能力。语言模型使用一种称为“自回归生成”的过程,以概率方式逐个单词生成输出。

语言模型的一个常见失败模式是在开始时输出一个错误答案,然后只输出可能证明该答案正确的信息(称为幻觉现象)。通过要求模型使用思维链来制定响应,你要求它从根本上改变语言模型对复杂问题得出结论的方式。
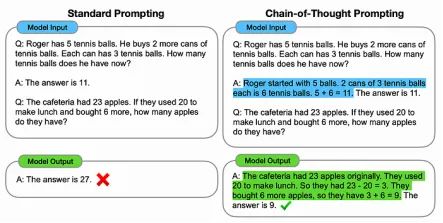
左侧的示例在标准提示下失败了,尽管模型完全相同。来源:https://arxiv.org/pdf/2201.11903.pdf
当所有信息都可用时,这种方法很好,但对于我们计算意大利最古老城市的累计年龄的示例,这种方法并不适用。如果我们的语言模型根本不知道城市的年龄,再怎么仔细推理也无法正确回答这个问题。
因此,有时仅有推理是不够的,还需要采取行动。
行动代理
在代理行为领域有两篇重要的论文:
- 做我能做的,而不是我说的:机器人功能中的基础语言链接:https://arxiv.org/pdf/2204.01691.pdf
- WebGPT:使用人工反馈的浏览器辅助问答链接:https://arxiv.org/pdf/2112.09332.pdf
这两者的核心思想是相同的:使语言模型能够与工具进行交互,从而使它们能够理解世界。让我们简要介绍一下这两种方法。
SayCan
做我能做的,而不是我说的(https://arxiv.org/pdf/2204.01691.pdf),这篇论文介绍了通常所说的“SayCan”架构。
想象一下,你正在尝试使用语言模型来控制一个机器人,并要求模型帮助你清理洒出来的饮料。大多数语言模型会提出完全合理的叙述。

这些叙述很好,但它们在控制机器人方面存在两个大问题:
- 响应必须对应于机器人能够执行的操作。没有某种“调用”功能,机器人无法调用清洁工。
- 考虑到机器人所处的当前环境,这种响应可能是完全不可行的。机器人可能有一个真空吸尘器附件,但机器人可能不在溢出物附近,因此无法使用真空吸尘器来清理溢出物。
为了解决这些问题,SayCan架构并行使用两个系统,通常称为“Say”和“Can”系统。
在现实世界环境中,机器人只能执行固定数量的操作。“Say”系统使用语言模型来决定这些预定义操作中哪一个是最合适的。
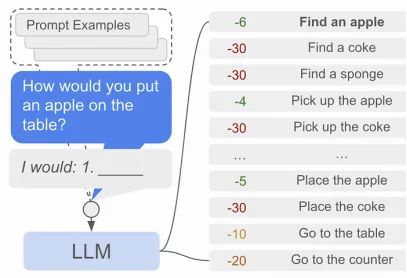
语言模型从可能的下一步操作列表中选择最适合的操作,来自SayCan论文 https://arxiv.org/pdf/2204.01691.pdf
语言模型的一个不太常见但非常有用的功能是对文本序列分配概率。要深入理解这个想法,需要一些数学和理论知识。
对于本文来说,只需知道,给定一些文本,语言模型可以分配一个该文本是否有意义的概率。这允许模型从可能的操作列表中选择其认为合适的操作。
某个操作可能在语言上合理,但对于像机器人这样的代理来说可能不可行。例如,语言模型可能会说“捡起一个苹果”,但如果没有苹果可捡,“找到一个苹果”是更合理的行动。SayCan架构的“Can”部分旨在解决这个特定问题。
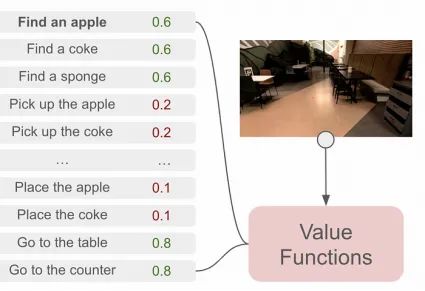
价值函数被训练来评估某个动作成功的可能性,来自SayCan论文https://arxiv.org/pdf/2204.01691.pdf
SayCan架构要求每个可能的动作与一个价值函数配对。价值函数输出一个动作成功执行的概率,从而定义了机器人“能”做什么。在这个示例中,“捡起苹果”不太可能成功,大概是因为机器人视野中没有苹果,因此“找到一个苹果”更为可行。计算某个动作可行性有几种方法;一种常见的方法是“优势演员评论家”,通常缩写为A2C。这超出了本文的范围,但我可能会在以后的文章中讨论。
SayCan架构使用语言模型认为的相关步骤,结合价值函数认为可能的步骤,来选择代理应采取的下一步行动。它会不断重复这个过程,直到给定的任务完成。
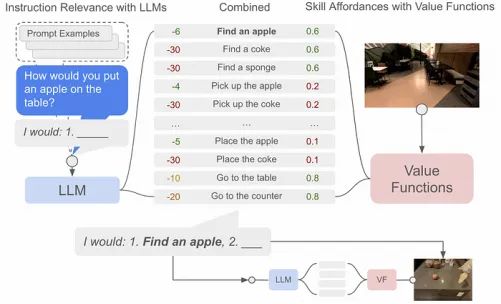
SayCan架构,结合了语言模型“says”的下一步和价值函数判断“can”可行执行的步骤,来自SayCan论文https://arxiv.org/pdf/2204.01691.pdf
WebGPT采用了与SayCan相似的一些理念,但增强了语言模型浏览互联网的能力。
WebGPT
你可能还记得几年前人们对AI进入互联网感到不安。WebGPT:使用人工反馈的浏览器辅助问答是原因(https://arxiv.org/pdf/2112.09332.pdf)。WebGPT的想法是训练GPT-3学习以类似于人类的方式浏览互联网。OpenAI 研究人员通过一种称为“行为克隆”的过程来实现这一目标。
研究人员给人类一个问题,并配有一个使用Bing搜索引擎的特殊纯文本浏览器,以及一个随机提示。
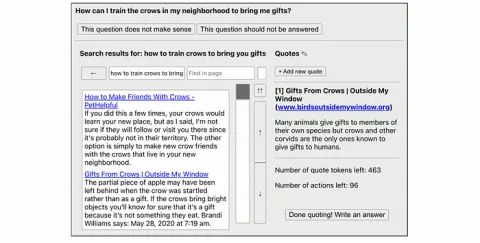
参与者使用的搜索界面,来自WebGPT论文 https://arxiv.org/pdf/2112.09332.pdf
人类被告知可以浏览互联网并记录一定数量的引述。然后,在整理这些引述后,他们可以写下问题的答案。大约有6000次这种浏览互联网的示范被收集起来,并用于微调一个现有的预训练语言模型。从这些数据中,GPT学会了如何从互联网上获取有用的数据。

WebGPT可用的命令,摘自WebGPT论文 https://arxiv.org/pdf/2112.09332.pdf
通过克隆基于人类示例的这种特定形式的操作,WebGPT本质上执行以下步骤:
- 收到提示
- 使用纯文本浏览器在互联网上搜索有关提示的信息
- 滚动浏览页面、关注链接并挑选出个别文本的引述
- 基于这些有用的引述构建一个上下文,并使用它来构建最终输出
这很好,但构建一个自定义的网页浏览器并微调一个价值百万美元的模型对于日常程序员来说并不完全可行。ReAct提供了非常相似的功能,基本上是免费的。
ReAct代理:推理与行动
在前面的章节中,我们讨论了推理提示策略,比如“思维链”,以及使模型能够与外部世界交互的行动策略,比如SayCan和WebGPT。
ReAct代理框架,正如《ReAct:语言模型中的协同推理和行动》(https://arxiv.org/pdf/2210.03629.pdf)中提出的,将推理和行动代理结合在一起,试图创建能够执行更复杂任务的更好的代理。
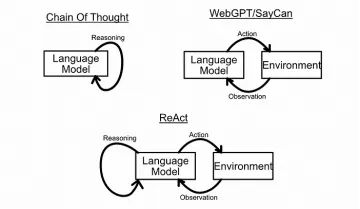
ReAct结合了思维链的推理概念,WebGPT和SayCan的行动概念,并将它们整合成一个整体系统。灵感来源https://react-lm.github.io/
其理念是为语言模型提供一组工具,使代理能够采取行动,然后使用上下文学习来鼓励模型使用思维链来推理何时以及如何使用这些工具。通过逐步制定计划并根据需要使用工具,ReAct代理可以完成一些非常复杂的任务。

一个提示的示例,以及来自不同提示策略的各种答案。可以看出,有时需要思维链和行动的结合才能回答复杂的问题。来源https://arxiv.org/pdf/2210.03629.pdf
ReAct的工作方式非常简单。实际上,你只需要三个组件:
- 提供如何进行 ReAct 提示的示例背景
- 模型可以根据需要决定使用哪些工具
- 解析,监视模型的输出并触发动作。
让我们通过自己构建一个ReAct系统来更好地理解这些子系统以及ReAct的工作方式。
使用LangChain在Python中实现ReAct
在这个例子中,我们将使用 LangChain构建一个可以阅读维基百科文章、处理上下文、解析和工具执行的代理。
本节将识别LangChain代理系统的一些问题。在下一节中,我将从头构建一个ReAct代理来改进这些问题。不过现在,我们可以通过使用LangChain对ReAct有一个实际的了解。
依赖项
首先,我们需要安装并导入一些依赖项:
!pip -q install langchain huggingface_hub openai google-search-results tiktoken wikipedia"""Importing dependencies necessary
"""
#for using OpenAI's GPT models
from langchain import OpenAI
#For allowing langchain to query Wikipedia articles
from langchain import Wikipedia
#for setting up an enviornmnet in which a ReAct agent can run autonomously
from langchain.agents import initialize_agent
#For defining tools to give to a language model
from langchain.agents import Tool
#For defining the type of agent
#there's not a lot of great documentation about agents in the LangChain docs
#I think this sets the context used to inform the model how to behave
from langchain.agents import AgentType
#again not a lot of documentation as to exactly what this does,
#but for our purposes it abstracts text documents into
#into a "search" and "lookup" function
from langchain.agents.react.base import DocstoreExplorerDocstore
首先,我们需要设置Docstore。坦白地说,这是LangChain中一个奇怪的部分,而且文档很少,所以要了解docstore到底是什么以及它是如何工作的可能有点难以捉摸。
Docstore似乎是任意文本文档存储的抽象,可以是网站的HTML、PDF的文本等。Docstore提供了两个重要功能:
- 搜索,在文档库中搜索特定文档
- 查找,根据关键字搜索文档中的特定文本部分
我们可以使用以下代码创建基于维基百科的文档库:
#defining a docstore, and telling the docstore to use LangChains
#hook for wikipedia
docstore=DocstoreExplorer(Wikipedia())然后我们就可以搜索一篇文章。
docstore.search('Dune (novel)')
该响应对应于同名的文章

我们可以使用查找功能来搜索关键字。如果我们搜索“Lawrence”,就会出现一些内容,因为Dune这本书深受历史人物“Lawrence of Arabia”的启发。
#Looking up sections of the article which contain the word "Lawrence"
docstore.lookup('Lawrence')
在我们继续之前值得注意的是,LangChain中的Wikipedia驱动程序基于PyPi上的Wikipedia模块,而PyPi又是MediaWiki API的包装器,这可能有点古怪。
#searching for the article "Dune" which failes even
#though there's an article named "Dune"
docstore.search('Dune')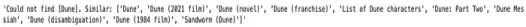
搜索“Dune”文本不起作用,即使有一篇名为“Dune”的文章是关于Dune的。这可能是好事,也可能是坏事,具体取决于上下文。奇怪的是,搜索“Dune”不起作用,即使有一篇名为“Dune”的文章。我注意到这个怪癖以前也让代理程序出错过。
#Searching for "Sand Dune" results in the article "Dune"
docstore.search('Sand Dune')
搜索“Sand Dune”返回了一篇名为“Dune”的文章,该文章与Dune有关。
如果你基于这个API使用一个代理,你可能会遇到这些怪癖带来的一些小问题。LangChain确实有一个自定义代理定义系统,可能允许你设计一些应对这些问题的稳健方法。不过,老实说,直接从头开始实现ReAct可能会更好,我们将在完成LangChain后进行这个操作。
工具
无论如何,抛开这些怪癖,我们有一个Docstore,可以根据关键词或短语搜索文档和查找文档中的部分内容。现在,现在我们将这些公开为 LangChain“工具”。
从LangChain的角度来看,工具是代理可以用来以某种方式与世界互动的功能。我们可以为我们的代理构建两个工具,一个用于搜索,一个用于查找。
tools = [
Tool(
name="Search",
func=docstore.search,
description="useful for when you need to ask with search"
),
Tool(
name="Lookup",
func=docstore.lookup,
description="useful for when you need to ask with lookup"
)
]当代理想要使用某个工具时,它会通过名称字段进行引用。func是使用工具时调用的实际函数,description是可选但推荐的描述,它可以帮助模型更好地理解工具的用途(这些描述的具体使用方式我不太清楚,文档也不太完善)。我使用了LangChain推荐的描述,但我相信你可以通过调整它们使描述更明确。
定义ReAct代理
现在我们已经设置了docstore和工具,我们可以定义要使用的LLM并设置一个代理。
llm = OpenAI(temperature=0, model_name="gpt-3.5-turbo-instruct")
react_agent = initialize_agent(tools, llm, agent=AgentType.REACT_DOCSTORE, verbose=True代理类型(AgentType)是什么以及它如何工作并不那么明显,而LangChain文档在这方面提供的信息也很少。我认为这与设置上下文有关。
语言模型能够理解我们的工具,是因为在初始化代理时,会自动创建一个上下文,其中展示了多个工具使用的示例。我很确定这只有在我们根据预定义的代理类型来定义工具时才有效,在这种情况下,预定义的代理类型是REACT_DOCSTORE。
如果我们打印出react_agent.agent.llm_chain.prompt.template(这是一个深层嵌套在react_agent初始化为REACT_DOCSTORE代理的变量),我们可以看到为我们的代理自动生成的上下文:
Question: What is the elevation range for the area that the eastern sector of the Colorado orogeny extends into?
Thought: I need to search Colorado orogeny, find the area that the eastern sector of the Colorado orogeny extends into, then find the elevation range of the area.
Action: Search[Colorado orogeny]
Observation: The Colorado orogeny was an episode of mountain building (an orogeny) in Colorado and surrounding areas.
Thought: It does not mention the eastern sector. So I need to look up eastern sector.
Action: Lookup[eastern sector]
Observation: (Result 1 / 1) The eastern sector extends into the High Plains and is called the Central Plains orogeny.
Thought: The eastern sector of Colorado orogeny extends into the High Plains. So I need to search High Plains and find its elevation range.
Action: Search[High Plains]
Observation: High Plains refers to one of two distinct land regions
Thought: I need to instead search High Plains (United States).
Action: Search[High Plains (United States)]
Observation: The High Plains are a subregion of the Great Plains. From east to west, the High Plains rise in elevation from around 1,800 to 7,000 ft (550 to 2,130 m).[3]
Thought: High Plains rise in elevation from around 1,800 to 7,000 ft, so the answer is 1,800 to 7,000 ft.
Action: Finish[1,800 to 7,000 ft]
...
Question: Were Pavel Urysohn and Leonid Levin known for the same type of work?
Thought: I need to search Pavel Urysohn and Leonid Levin, find their types of work, then find if they are the same.
Action: Search[Pavel Urysohn]
Observation: Pavel Samuilovich Urysohn (February 3, 1898 - August 17, 1924) was a Soviet mathematician who is best known for his contributions in dimension theory.
Thought: Pavel Urysohn is a mathematician. I need to search Leonid Levin next and find its type of work.
Action: Search[Leonid Levin]
Observation: Leonid Anatolievich Levin is a Soviet-American mathematician and computer scientist.
Thought: Leonid Levin is a mathematician and computer scientist. So Pavel Urysohn and Leonid Levin have the same type of work.
Action: Finish[yes]
Question: {input}
{agent_scratchpad}为了提高可读性,我减少了上下文的大小,但它由六个示例(展示了其中的两个)以及用户的问题组成。这个上下文使语言模型能够理解ReAct的一般结构,并引导它遵循“思考”(Thought)、“行动”(Action)和“观察”(Observation)格式,同时展示“搜索”(Search)和“查找”(Lookup)工具的示例。
执行我们的ReAct代理
好了,我们设置了Docstore(这是一个访问维基百科文章的API),定义了工具,并初始化了代理。现在我们可以运行它了。
prompt = "What is the age of the president of the United States? The current date is Dec 26 2023."
react_agent.run(prompt)
注意:我在提示中提供了日期,因为该模型(GPT3.5)是基于几年前的数据进行训练的,并且可能假设“现在”是2021-2022年
代理将问题分解为一系列步骤,并使用维基百科搜索信息。
我尝试了我们的累积城市年龄测试,但没有取得太大的成功。
from langchain.chat_models import ChatOpenAI
prompt = "Calculate the cumulative age of the oldest cities in all the regions in Italy. You have access to wikipedia given the 'search' and 'lookup' tools."
llm = ChatOpenAI(temperature=0, model_name="gpt-4-1106-preview")
react_agent = initialize_agent(tools, llm, agent=AgentType.REACT_DOCSTORE, verbose=True)
react_agent.run(prompt)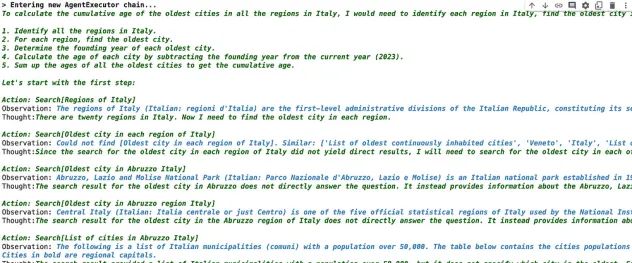
代理卡在了某个特定的搜索结果上,然后输出了以下内容:
阿布鲁佐最古老城市的搜索结果未提供所需信息。似乎在意大利每个地区找到最古老的城市是一项复杂的任务,可能无法使用提供的搜索工具轻松完成。它可能需要广泛的研究和历史记录的交叉引用,这超出了简单搜索查询的范围。鉴于这项任务的复杂性和搜索工具的局限性,可能无法以这种格式计算意大利所有地区最古老城市的累计年龄。更实用的方法是查阅综合历史数据库或已经汇编了此信息的学术来源。
这导致了解析错误,因为此响应不符合LangChain期望的“行动”、“观察”和“思考”结构。这是一种在ReAct论文中直接提到的失败模式,他们将其归因于工具提供的低质量或不相关信息。
在这个时候,LangChain的抽象从方便变成了障碍。显然,维基百科API不足以解决这个问题,但由于LangChain在这一主题上的文档不完善,如何改进这一点被留给了读者自己去探索。
看起来从头开始实现ReAct不仅可能更清晰,而且更容易且性能更好。让我们试试看吧!
从Scratch开始使用Python进行ReAct
我们将使用很多在LangChain中看到的相同范式,但尝试使组件不那么晦涩。另外,我们将使用Bing搜索而不是MediaWiki API。LangChain确实有一个不错的BingSearch封装,因此我们将使用LangChain来帮助我们处理这个问题,但我们会自己完成所有ReAct的工作。
完整的从头实现ReAct的代码可以在这里找到。
安装依赖项
我们将使用LangChain的Bing搜索包装器和OpenAI模型。
!pip install langchain
!pip install openai"""Testing out Bing Search
"""
from langchain.utilities import BingSearchAPIWrapper
search = BingSearchAPIWrapper()
print(search.run("how many regions are there in italy?"))
设置工具
我们构建的所有内容都将围绕代理可以使用的工具及其行为方式展开。所以,我们将先构建这些工具。
在这个例子中,我们将构建两个工具:一个允许模型通过Bing搜索互联网,另一个允许模型与计算器交互。由于这些都是供GPT使用,即语言模型,因此这两个工具都将输入和输出文本。
"""Bing Search Tool
"""
def BSearch(input):
"""expects any arbitrary text
"""
search = BingSearchAPIWrapper()
return search.run(input)"""Calculator Tool
takes in an arbitrary algebreic expression, as a string, and outputs a result as a string.
"""
import ast
import operator as op
def calculate(input):
"""Computes the result of an arbitrary algebreic expression
inspired by an answer in:
https://stackoverflow.com/questions/2371436/evaluating-a-mathematical-expression-in-a-string
"""
# supported operators
operators = {ast.Add: op.add, ast.Sub: op.sub, ast.Mult: op.mul,
ast.Div: op.truediv, ast.Pow: op.pow, ast.BitXor: op.xor,
ast.USub: op.neg}
#helper function for evaluating an algebreic expression
def eval_(node):
match node:
case ast.Constant(value) if isinstance(value, int):
return value # integer
case ast.BinOp(left, op, right):
return operators[type(op)](eval_(left), eval_(right))
case ast.UnaryOp(op, operand): # e.g., -1
return operators[type(op)](eval_(operand))
case _:
raise TypeError(node)
return 'result of "{}": {}'.format(input, str(eval_(ast.parse(input, mode='eval').body)))我们在这里会从LangChain获取一些灵感,为每个工具定义一个“名称”和“描述”,然后将其传递给模型。
"""Defining names and descriptions for each tool
"""
tools = [
{'name': 'BSearch',
'description': 'Search Bing, a powerful search engine, for information about an input',
'function': BSearch},
{'name': 'Calculate',
'description': 'calculate the result of an algebreic expression',
'function': calculate}
]设计代理
ReAct从学术角度来看是一个框架。它不是一套简单明了的步骤,而是一种促进语言模型的方法论。
该准则更像是所谓的“指导方针”,而不是实际的规则。——《加勒比海盗》中的巴博萨
因此,在实施ReAct时,某些方面需要根据具体情况进行解释。例如,ReAct的一个核心思想是,行动及其触发的工具可能会输出大量无用信息。“观察”任务是提取和精炼相关信息,以避免污染代理的推理过程。然而,具体如何实现这一点并没有严格定义。
我选择将ReAct代理分为两种状态:“工作”状态和“行动和观察”状态。工作状态是正常的ReAct式思维过程,如下所示:
Question: Musician and satirist Allie Goertz wrote a song about the "The Simpsons" character Milhouse, who Matt Groening named after who?
Thought: The question simplifies to "The Simpsons" character Milhouse is named after who. I only need to search Milhouse and find who it is named after.
Action: BSearch[Milhouse]
Observation: Milhouse Mussolini Van Houten is a recurring character in the Fox animated television series The Simpsons voiced by Pamela Hayden and created by Matt Groening.
Thought: The paragraph does not tell who Milhouse is named after, maybe I can search "who is Milhouse from The Simpsons named after".
Action: BSearch[who is Milhouse from The Simpsons named after]
Observation: Milhouse was named after U.S. president Richard Nixon, whose middle name was Milhous.
Thought: Milhouse was named after U.S. president Richard Nixon, so the answer is Richard Nixon.
Action: Finish[Richard Nixon然而,我们还需要一种方法来获取模型“Action: BSearch[Milhouse]”的输出,并让模型生成合理的提炼。为此,我定义了一个单独的状态,专注于生成这些观察结果。
Thought: Arthur’s Magazine was started in 1844. I need to search First for Women next.
Action: BSearch[First for Women]
Action Result: 270 Sylvan Avenue, Englewood Cliffs, NJ 07632 Email address: <b>contactus</b>@<b>firstforwomen</b>.com About Us To find out more about <b>First</b> For <b>Women</b> online, visit our About Us page. Contact <b>First</b> for <b>Women</b> for subscription questions, general inquiries, tips, help and more at our email address or via phone. Free Stuff: Enter every day to win the hottest fashion, accessories, technology and more at <b>First</b> For <b>Women</b>! 10<b> DIY</b> Holiday Nail Designs That Add Festive Flair to Your Fingertips — In 3 Steps or Less! You're sure to find one that makes you shine! Cooking Hacks Chef’s Easy Trick Fixes Warped Pans So They’re Good as New + Tips for Avoiding It This *DIY on a dime* fix is cheaper than buying a new baking sheet or skillet!
Observation: First for Women offers free things, advice, cooking tips, and other articles.这种状态在模型输出一个“行动”时被触发。总体上,工作方式如下:
- 在“工作”状态下,模型可能决定执行需要“工具”的“行动”
- 当这种情况发生时,我们就会转变为“行动和观察”状态
- 该工具被触发,产生如上例所示的“操作结果”
- 触发工具,导致如上例中的“行动结果”
- 触发行动的想法、行动本身以及行动的结果都结合在一起。然后提示模型进行观察
- 这个观察结果随后被添加到工作状态中。因此,工作状态包含了工具使用的精炼信息,而不带有所有工具输出的负担
定义上下文
为了让模型按照我们的意愿行事,ReAct使用了思维链提示。通过向模型提供解决问题的示例,我们可以促使模型运用工具进行推理。因为我们有两个状态,即“工作”状态和“行动和观察”状态,所以我们需要两组示例来说明模型在每个状态下应如何表现。这些示例有点长,你可以参考代码来查看完整的上下文,但以下是每个示例的片段:
working_context_examples = [
{"role": "user", "content": "Question: What is the elevation range for the area that the eastern sector of the Colorado orogeny extends into?"},
{"role": "assistant", "content": "Thought: I need to search Colorado orogeny, find the area that the eastern sector of the Colorado orogeny extends into, then find the elevation range of the area."},
{"role": "assistant", "content": "Action: BSearch[Colorado orogeny]"},
{"role": "assistant", "content": "Observation: The Colorado orogeny was an episode of mountain building (an orogeny) in Colorado and surrounding areas."},
{"role": "assistant", "content": "Thought: It does not mention the eastern sector. So I need to look up eastern sector."},
{"role": "assistant", "content": "Action: BSearch[Colorado orogeny eastern sector]"},
{"role": "assistant", "content": "Observation: The eastern sector extends into the High Plains and is called the Central Plains orogeny."},
{"role": "assistant", "content": "Thought: The eastern sector of Colorado orogeny extends into the High Plains. So I need to search High Plains and find its elevation range."},
{"role": "assistant", "content": "Action: BSearch[High Plains]"},
{"role": "assistant", "content": "Observation: High Plains refers to one of two distinct land regions"},
{"role": "assistant", "content": "Thought: I need to instead search High Plains (United States)."},
{"role": "assistant", "content": "Action: BSearch[High Plains (United States)]"},
{"role": "assistant", "content": "Observation: The High Plains are a subregion of the Great Plains. From east to west, the High Plains rise in elevation from around 1,800 to 7,000 ft (550 to 2,130 m).[3]"},
{"role": "assistant", "content": "Thought: High Plains rise in elevation from around 1,800 to 7,000 ft, so the answer is 1,800 to 7,000 ft."},
{"role": "assistant", "content": "Action: Finish[1,800 to 7,000 ft]"},
{"role": "user", "content": "Question: Add 3, 6, and 9. Take that sum, multipy it by two, and add seventeen"},
{"role": "assistant", "content": "Thought: I need to find the sum of 3,6, and 9, then I need to take that sum and multiply it by 2, then I need to take the product and add 17"},
{"role": "assistant", "content": "Action: Calculate[3+6+9]"},
{"role": "assistant", "content": "Observation: The result is 18"},
{"role": "assistant", "content": "Thought: I need to multiply 18 by 2"},
{"role": "assistant", "content": "Action: Calculate[18*2]"},
{"role": "assistant", "content": "Observation: The result is 36"},
{"role": "assistant", "content": "Thought: I need to add 36 and 17"},
{"role": "assistant", "content": "Action: Calculate[36+17]"},
{"role": "assistant", "content": "Observation: The result is 53"},
{"role": "assistant", "content": "Thought: The calculation is done, so the answer is 53"},
{"role": "assistant", "content": "Action: Finish[53]"}
]action_observation_examples = [
{"role": "assistant", "content": "Thought: It does not mention the eastern sector. So I need to look up eastern sector."},
{"role": "assistant", "content": "Action: BSearch[Colorado orogeny]"},
{"role": "system", "content": "Action Result: The <b>eastern</b> <b>sector</b> extends into the High Plains and is called the Central Plains <b>orogeny</b>. The boundary between the <b>Colorado orogeny</b> and the Wyoming craton is the Cheyenne belt, a 5-km-wide mylonitic shear zone that verges northward. The Cheyenne belt transects and cuts off the south edge of the older Trans-Hudson <b>orogeny</b>. [2] Introduction Acknowledgments Geologic framework <b>Colorado</b> province Structure <b>Colorado</b> <b>orogeny</b> Berthoud <b>orogeny</b> Uncompahgran disturbance of Snake River-Wichita tectonic zone Clastic metasedimentary rocks of Proterozoic age Reactivation of Proterozoic shear zones Magnetic patterns Regional significance of northeast shear zones Tectonic Action 1 Search [<b>Colorado</b> <b>orogeny</b>] Observation 1 The <b>Colorado</b> <b>orogeny</b> was an episode of mountain building (an <b>orogeny</b>) in <b>Colorado</b> and surrounding areas. Thought 2 It does not mention the <b>eastern</b> <b>sector</b>."},
{"role": "assistant", "content": "Observation: The eastern sector extends into the High Plains and is called the Central Plains orogeny."},
{"role": "assistant", "content": 'Thought: Arthur’s Magazine was started in 1844. I need to search First for Women next.'},
{"role": "assistant", "content": 'Action: BSearch[First for Women]'},
{"role": "system", "content": 'Action Result: 270 Sylvan Avenue, Englewood Cliffs, NJ 07632 Email address: <b>contactus</b>@<b>firstforwomen</b>.com About Us To find out more about <b>First</b> For <b>Women</b> online, visit our About Us page. Contact <b>First</b> for <b>Women</b> for subscription questions, general inquiries, tips, help and more at our email address or via phone. Free Stuff: Enter every day to win the hottest fashion, accessories, technology and more at <b>First</b> For <b>Women</b>! 10<b> DIY</b> Holiday Nail Designs That Add Festive Flair to Your Fingertips — In 3 Steps or Less! You're sure to find one that makes you shine! Cooking Hacks Chef’s Easy Trick Fixes Warped Pans So They’re Good as New + Tips for Avoiding It This *DIY on a dime* fix is cheaper than buying a new baking sheet or skillet!'},
{"role": "assistant", "content": 'Observation: First for Women offers free things, advice, cooking tips, and other articles.'}
]许多“工作上下文”示例受到LangChain中示例的启发,但经过修改以匹配我指定的工具。而“行动观察”示例则基于行动及其实际结果,这些结果在“工作上下文”中已经存在。这些上下文深刻影响了代理的行为,因此通常需要调整这些示例,以确保代理能够正确地执行任务。
定义代理
现在我们已经定义了工具,设计了代理的一般框架,并且定义了上下文,让我们开始吧。我将我的代理定义为一个类,它具有许多小的功能,如果逐一讲解将会很繁琐。在本文中,我们将介绍一些重要的要点,但如果想获取更多信息,请查看代码。
初始化
当代理初始化时,会发生一些重要的事情。首先,我们设置一个状态变量来帮助我们跟踪代理是“思考”、“行动”还是“观察”。我们在开始时将代理初始化为“问题”。
#state loops through "thought", "action", and "observation" as ReAct works
self.current_state = 'Question'接下来,我们定义上下文。我们之前已经定义了上下文示例,但我们要通过提供工具信息、模型说明等内容来进一步充实上下文。
#this gets built out as thoughts, actions, and observations are made
self.working_context = [
{"role": "system", "content": "You are a helpful assistant whos job it is to answer a users question by breaking that question into logical steps, then following those steps by thought, action, and observation. Only perform one Thought or Action."},
{"role": "system", "content": "When performing an Action you can only use one of the following tools: {}".format([t['name']+', which is used for ' +t['description'] for t in self.tools])}
]+working_context_examples + [{"role": "user", "content": 'Question:'+question}]
#This is used to tell the system how to behave when observing the result of an action
self.observe_context = [
{"role": "system", "content": "You are a helpful assistant whos job it is to analyze information provided by the system, given a users thought, and return an observation which distills knowledge useful to the thought based on information from the system information."},
]+action_observation_examples工作状态提示
在建立状态管理系统之前,我们先来了解一下每个状态的作用。当处于工作状态时(也就是模型输出任何操作以外的内容时),我们可以直接要求模型继续当前的思维链。这看起来像这样:
def prompt_model_working(self):
"""Prompt a model within the normal working memory
The distinction here is that, when prompted to act, the model
operates outside of the working memory to make an observation. This
function is not that; this function prompts the model to organically
make thoughts and actions based on the working context.
"""
#querying the model
client = OpenAI()
response = client.chat.completions.create(
model=self.model,
messages=self.working_context
)
#reformatting response into appropriate format
response = {"role": "assistant", "content": response.choices[0].message.content}
print(self.working_context)
print('==========')
print(response)
#adding result to the working context
self.working_context.append(response)行动和观察
当工作状态提示触发了一个动作(通过模型输出它想要执行一个动作)时,执行和观察函数会做几件事:
- 解析动作。因此,它会获取工具名称和工具输入。
- 根据解析出的输入执行工具。
- 然后,它会构建一个包含“想法”、“行动”和“行动结果”的上下文,这些上下文与行动相关,同时还包含我们之前定义的“行动观察示例”中的行动和观察示例。
- 利用该上下文,它会要求OpenAI LLM生成一个提示。
生成的观察结果将被添加到工作上下文中。
def act_and_observe(self):
"""Triggers an action, then gets the model to generate an observation
An action, like searching for an article, can trigger a lot of text.
In order to save on the size of the context window, the model is asked
to make an "observation" based on the response of the action. That
observation is added to the working context.
"""
#getting the most recent action request from the model
action_request = self.text_after_colon(self.working_context[-1]['content'])
#parsing action
bracket_index = action_request.find('[')
if bracket_index != -1:
action = action_request[:bracket_index]
else:
raise ValueError("Improperly Formatted Action Request: {}".format(action_request))
#parsing the action argument
action_argument = re.findall(r"\[(.*?)\]", action_request)
action_argument = action_argument[0] if action_argument else ""
#The action is "finish", meaning the model is outputting the result
if action == "finish":
#Note: because this is a demo, I'm just running it step by step.
pass
#The model requested a tool to be used
action_result=None
for tool in self.tools:
if tool['name'] == action:
#found the correct toll, executing
action_result = tool['function'](action_argument)
break
else:
#the tool could not be found
raise ValueError("Tool could not be found from action request: {}".format(action_request))
#an observation must be generated based on the result of the tool use
#building out the relevant context
#using the most recent "thought" and "action" to help construct
context = self.observe_context+self.working_context[-2:]+[
{"role": "system", "content": "Action Result: {}".format(action_result)},
]
#generating an observation based on the user thought and system info
#the user thought being the thought which sparked the usage of the
#tool that created the system info
client = OpenAI()
response = client.chat.completions.create(
model=self.model,
messages=context
)
#reformatting response into appropriate format
response = {"role": "assistant", "content": response.choices[0].message.content}
#adding result to the working context
self.working_context.append(response)定义状态管理和执行
我跳过了代理的一些次要功能,但我们涵盖了所有主要部分。现在,我们可以把它们组合在一起了。我选择将代理的执行封装为“步骤”。一个步骤定义为以下一系列操作:
- 根据代理的最新状态,决定是触发工作提示还是采取行动并进行观察
- 更新代理状态。
def execute_step(self):
"""Execute a single step of the agent
"""
self.iter += 1
if self.iter > self.n:
#Stopping execution, exceeded iteration cap
raise ValueError("Too Many Iterations")
model_response = None
match self.current_state:
#the model has not executed yet, executing first model iteration
case 'Question':
#getting the model to generate the next output
model_response = self.prompt_model_working()
#handling when a thought has just occured
case 'Thought':
#getting the model to generate the next output
model_response = self.prompt_model_working()
#handling when an action request has just occured
case 'Action':
#triggering the relevant action, then prompting the model
#to make an observation about that action
model_response = self.act_and_observe()
#handling when an observation has just occured
case 'Observation':
#getting the model to generate the next output
model_response = self.prompt_model_working()
#invalid operation type
case _:
raise ValueError("Unknown operation type '{}'".format(self.current_state))
print('model response')
print(model_response)
#parsing out the response type from the model
self.current_state = self.text_before_colon(model_response['content'])
return model_response测试代理
不错!代理完成了。同样,我忽略了一些东西,但我们已经涵盖了主要细节。让我们看看我们的代理在“意大利古城的累计年龄”测试中是否更胜一筹。
因为这只是一个测试,所以我选择使用两个代码块来逐步运行代理:
question = 'What is the cumulative age of the oldest cities in all the regions in italy? Hint: search for the regions of italy first'
a = Agent(question, tools, working_context_examples, action_observation_examples, model="gpt-4-1106-preview")#running a single step. This code block can get re-run to progress the agent
resp = a.execute_step()我们可以运行几次,直到模型输出“完成”动作。然后,我们可以打印出工作上下文,以了解代理做得如何。我对输出进行了清理,使其更易于人阅读:
#only printing out the thought process, not the context used to inform the model
for i, element in enumerate(a.working_context[68:]):
print('{} - {}'.format(i,element['content']))结果输出如下:
0 - Question:What is the cumulative age of the oldest cities in all the regions in italy? Hint: search for the regions of italy first
1 - Thought: First I need to identify all the regions in Italy and then find the oldest city in each region. Then, I can calculate the cumulative age for all those cities. Let's begin by searching for the regions in Italy.
2 - Action: BSearch[regions of Italy]
3 - Observation: Italy is divided into 20 administrative regions, which correspond generally with historical traditional regions.
4 - Thought: Now I need to find the oldest city in each of the 20 regions of Italy. I will start by searching for the oldest city in one region and repeat this process for each region, one at a time.
5 - Action: BSearch[oldest city in each region of Italy]
6 - Observation: Matera is noted as one of the oldest continuously inhabited cities, not just in Italy but also in Europe. It is in the Basilicata region of Italy. For a comprehensive understanding, a similar search would need to be conducted for each of the 20 Italian regions to identify the oldest city in each.
7 - Thought: I have found the oldest city in one of the Italian regions, but I need to continue and find the oldest city in the remaining 19 regions. I can continue by searching for the oldest city in another region of Italy.
8 - Action: BSearch[oldest city in Abruzzo Italy]
9 - Observation: Chieti is widely believed to be one of the oldest cities in Italy and originates from ancient civilizations in the Abruzzo region.
10 - Thought: Now I have the oldest city from Abruzzo (Chieti), and before I had for Basilicata (Matera). I need to continue this research to find the oldest cities in the 18 remaining Italian regions. Let's proceed with another region.
11 - Action: BSearch[oldest city in Aosta Valley Italy]
12 - Observation: Aosta is the principal city of the Aosta Valley and is likely one of the oldest in the region, given its historical significance and central location.
13 - Thought: I have now the oldest cities in three Italian regions: Matera for Basilicata, Chieti for Abruzzo, and Aosta for Aosta Valley. To find the oldest city for the rest of the regions, I would need to repeat the procedure for each one, and then calculate the cumulative age. The next step is to find the oldest city in the fourth region of Italy. However, this process is quite lengthy; to provide a complete answer, we would need to finish gathering the data for all regions. But since the process is clear, let's proceed with the next oldest city search.
14 - Action: BSearch[oldest city in Apulia Italy]
15 - Observation: The search result specifically mentions Matera as one of the oldest continually inhabited towns in Italy and possibly the oldest in Europe. It has been inhabited for over 9,000 years. While Matera is in the Basilicata region, the search was intended to find the oldest city in Apulia (Puglia) Italy. Ostuni in Apulia is noted as one of the richest archaeological regions and was first colonized by Mycenaean Greeks. However, the search result does not clearly state that Ostuni is the oldest city in Apulia. Additional research may be needed to definitively identify the oldest city in the Apulia region of Italy.
16 - Thought: The information about Ostuni in Apulia suggests it has significant archaeological history, but it is not explicitly stated as the oldest city. This means I may need to continue searching to ensure accuracy. Alternatively, I can proceed with this assumption or move on to finding the oldest city in another Italian region. Since the original task is to establish the cumulative age of the oldest cities in all regions, and assuming Ostuni as the oldest city in Apulia may lead to an incorrect final result, it would be best to search again to confirm the oldest city in Apulia before moving on.
17 - Action: BSearch[oldest city in Puglia]
18 - Observation: Matera, which is in the region of Basilicata and not Puglia, is noted as the oldest city in Italy and Europe, with a history of continuous occupation dating back to the Palaeolithic period. For the region of Puglia (Apulia), cities like Bari and Egnazia display rich archaeological history, but there is no definitive statement in the given source that explicitly names the oldest city in Puglia. Therefore, additional research may be required to confirm the oldest city specifically in Puglia.
19 - Thought: The search for the oldest city in Puglia returned information about Matera again, which is in Basilicata, not Puglia. Since the search seems to be providing redundant results, it may require a different search strategy or deep diving into specific historical records to accurately identify the oldest city in Puglia. Since this is proving complex and the process to establish the cumulative age of the oldest cities in all Italian regions is lengthy and would require accumulating a significant amount of data, it may be best to guide the user on how to proceed with the research rather than continue the step-by-step process here.
20 - Action: Finish[Guide the user on research strategy]当我开始撰写这篇文章时,我并没有意识到这项任务有多么艰巨。意大利有很多大区,其中很多大区的历史非常古老而模糊。此外,网上还有很多冗余信息。即使让人准确回答这个问题也很困难。
话虽如此,我还是希望你们能理解我们的决策过程是多么的完美。通过使用拥有丰富百科知识的GPT-4,ReAct可以生成一些非常有力的上下文假设。
让我们再来看几个例子。
Ex1)用变量解决数学单词问题
问题
这个等式显示了Lucas从课后工作中获得的收入如何取决于他工作的小时数:e=12h。变量h代表他工作的小时数。变量e表示他赚了多少钱。Lucas工作6小时后能挣多少钱?—数据来源https://www.prodigygame.com/main-en/blog/math-word-problems/
代理回答:
0 - Question:This equation shows how the amount Lucas earns from his after-school job depends on how many hours he works:e = 12h. The variable h represents how many hours he works. The variable e represents how much money he earns. How much money will Lucas earn after working for 6 hours?
1 - Thought: I need to substitute h by 6 and calculate e
2 - Action: Calculate[12*6]
3 - Observation: Substituting h with 6, the calculation of 12h (12*6) yields the result of 72.
4 - Thought: The calculation is complete, so the answer is 72. Lucas will earn $72 after working for 6 hours.
5 - Action: Finish[72]Ex2)解一道有多次运算的数学题
问题
Aaron的糖果盒高20厘米,长10厘米,宽10厘米。Bruce的容器高25厘米,长9厘米,宽9厘米。求每个容器的体积。根据体积,谁的容器能装更多的糖果?—来源https://www.prodigygame.com/main-en/blog/math-word-problems/
代理回答:
0 - Question:Aaron’s candy container is 20 centimetres tall, 10 centimetres long and 10 centimetres wide. Bruce’s container is 25 centimetres tall, 9 centimetres long and 9 centimetres wide. Find the volume of each container. Based on volume, whose container can hold more candy?
1 - Thought: I need to calculate the volume of each container. The volume of a rectangular prism (which both containers seem to be, given they have measurable heights, lengths, and widths) is calculated by multiplying the height by the length by the width. After I calculate the volume of both containers, I can then compare the volumes to determine which container can hold more candy. Let's calculate the volume for Aaron's container first.
The formula for volume is V = l × w × h, where l is length, w is width, and h is height.
For Aaron's container: V = 20 cm (height) × 10 cm (length) × 10 cm (width).
Let's calculate that now.
2 - Action: Calculate[20*10*10]
3 - Observation: Aaron's container has a volume of 2000 cubic centimeters (cm³).
4 - Thought: Now I need to calculate the volume for Bruce's container using the same formula: V = l × w × h
For Bruce's container: V = 25 cm (height) × 9 cm (length) × 9 cm (width).
Let's calculate that.
5 - Action: Calculate[25*9*9]
6 - Observation: The volume of Bruce's container is 2025 cubic centimeters (cm³).
7 - Thought: Now that I have both volumes, I can compare them. Aaron's container volume is 2000 cm³ and Bruce's container volume is 2025 cm³. Bruce's container can hold slightly more candy since 2025 cm³ > 2000 cm³.
8 - Action: Finish[Bruce's container]Ex3)用多种方法解决难题
问题
世界上最北的城镇与世界上最南的城镇之间的距离是多少?
0 - Question:What is the distance between the most northern town in the world, and the most southern town in the world?
1 - Thought: The most northern town in the world is Longyearbyen, Svalbard, Norway; the most southern town is Puerto Toro, Chile. I need to search for the distance between Longyearbyen and Puerto Toro.
2 - Action: BSearch[distance between Longyearbyen and Puerto Toro]
3 - Observation: The distance between Longyearbyen, Svalbard, Norway, and Puerto Toro, Chile is not directly provided in the search result. However, with Longyearbyen being situated at 78°13′ N and 818 miles from the North Pole, and Puerto Toro located at 55°05′00″S on the eastern coast of Navarino Island, one would need to utilize a distance calculator tool or perform a more targeted search to determine the direct or travel distance between these two locations.
4 - Thought: I need to search for a more direct answer or use a geographic distance calculator to determine the distance between Longyearbyen and Puerto Toro. Since I don't have access to such a tool, I can only perform a search. I will adjust the search terms to hopefully yield a result that directly states the distance.
5 - Action: BSearch[distance from Longyearbyen, Norway to Puerto Toro, Chile]
6 - Observation: The distance between Longyearbyen, Norway, and Puerto Williams, Chile (close to Puerto Toro), is approximately 15784.4 kilometers (km). Note that this figure may represent a direct air travel distance and actual travel distance could vary depending on the route taken.
7 - Thought: The distance provided is for Longyearbyen to Puerto Williams, which is near Puerto Toro. The actual distance would be very slightly more than this, but for most intents and purposes, this distance would suffice as a good estimate for the distance between the most northern and the most southern towns in the world. The answer is approximately 15,784.4 kilometers.
8 - Action: Finish[Approximately 15,784.4 kilometers]GPT4中的代理
简要说明
GPT4是封闭源代码,因此很难准确了解其幕后情况。不过,有了ReAct的知识,我们可以更好地理解GPT4的一些行为。
当我们向GPT4询问累积的意大利城市年龄问题时,它首先会给出以下回复。

然后,它就会进行任何“分析”,并做出如下回应:

在我看来,这与我们之前讨论过的ReAct代理框架非常相似。
值得注意的是,GPT4在执行这项任务时并不稳定。我运行了几次,有时似乎会陷入无用的搜索结果中。不难理解,当使用语言模型自主决定搜索内容和步骤时,可能会出现这类问题。

举例说明,GPT4在某个古城问题上陷入困境,而在之前的同类问题中,这并不是一个问题。
结论
就是这样,向坚持下来的人们致敬!
在本文中,我们讨论了一些先进的单一提示方法,如思维链和检索增强生成。我们讨论了这些单一提示方法有时是不够的,有些问题需要迭代操作才能解决,并讨论了SayCan和WebGPT如何用于从环境中迭代请求额外信息。
然后,我们区分了迭代推理和与环境的迭代交互,并从这个角度探讨了ReAct代理框架。我们创建了两个既能进行语言推理,又能与世界互动以获取新信息的代理。我们在LangChain中创建了一个ReAct代理,它设置起来很快,但实际效果有限;我们还在Python中从头开始创建了一个ReAct代理,它更复杂一些,但也更容易理解和定制。
感谢阅读!你还可以订阅我们的YouTube频道,观看大量大数据行业相关公开课:https://www.youtube.com/channel/UCa8NLpvi70mHVsW4J_x9OeQ;在LinkedIn上关注我们,扩展你的人际网络!https://www.linkedin.com/company/dataapplab/。
原文作者:Daniel Warfield
翻译作者:文玲&诗彤&Qing
美工编辑:过儿
校对审稿:Jason
原文链接:https://towardsdatascience.com/llm-agents-intuitively-and-exhaustively-explained-8905858e18e2





