
面向对象的数据科学:重构代码
对于数据科学家来说,代码是分析和决策的支柱。随着数据科学应用变得越来越复杂,从嵌入软件的机器学习模型到编排大量信息的复杂数据管道,开发干净、有组织和可维护的代码变得至关重要。面向对象编程(OOP)释放了灵活性和效率,使数据科学家能够敏捷地响应不断变化的需求。
OOP引入了类的概念,类是创建封装数据和操作数据对象的方案。这种范式转变使数据科学家能够超越传统的函数式方法,促进模块化设计和代码可重用性。
在本文中,我们将探讨通过创建类和部署面向对象技术重构数据科学代码的好处,以及这种方法如何增强模块化和可重用性。如果你想了解更多关于编程的相关内容,可以阅读以下这些文章:
数据科学家提高Python代码质量指南
10个很棒的开源AI项目——私人AI、代码修复等
ChatGPT代码解释器:这里有10个令人惊叹的用例!
动动小手,几行python代码让你的邮箱自动化又智能!
数据科学中类的力量
在传统的数据科学工作流中,函数一直是封装逻辑的方法。这通常是足够的,因为函数允许开发人员最大程度地减少重复的代码。然而,随着项目的发展,维护大量的函数集合可能会导致代码难以导航、调试和扩展。
这就是类发挥作用的地方。类是创建对象的方案,这些对象将数据和操作该数据的函数封装在一起。通过将代码组织到类中,开发人员可以获得以下优势:
- 模块化和封装:类通过将相关功能分组在一起来促进模块化。每个类封装了自己的属性(数据)和方法(函数),减少了全局变量污染的风险和命名冲突的可能性。这有助于保持关注点的清晰分离,使代码更容易理解和修改。
- 可重用性:类通过为项目的不同部分提供一致的接口,鼓励可重用性。一旦定义了一个类,就可以在需要的时候实例化它,并且可以使用它的方法来获得一致的结果。
- 继承和多态性:继承允许开发人员创建从父类继承属性和方法的子类。这促进了代码重用,同时支持针对特定任务进行定制。多态性是另一个面向对象的概念,它允许开发人员在不同的类中使用相同的方法名,根据特定的实现调整行为。
- 测试和调试:类促进了单元测试,因为测试用例可以针对类中的单个方法,从而更容易识别和修复问题,提高了代码库的整体稳定性。
重构为类:一个理论例子
让我们考虑这样一个场景:您正在处理一个涉及数据预处理、模型训练和评估的机器学习项目。最初,你可能会为每个步骤编写一个函数集合:
# Example: Using functions for data preprocessing
def load_data(file_path):
# Load and preprocess data
...
def preprocess_data(data):
# Clean, transform, and encode data
...
def train_model(preprocessed_data):
# Train a machine learning model
...
def evaluate_model(trained_model, test_data):
# Evaluate model performance
...虽然函数分解是有效的,但随着时间的推移,在预处理、训练和评估中可能会出现许多步骤。这可能会对管理这些函数带来挑战。
将代码重构为类:
def load_data(self, file_path):
# Load data
...
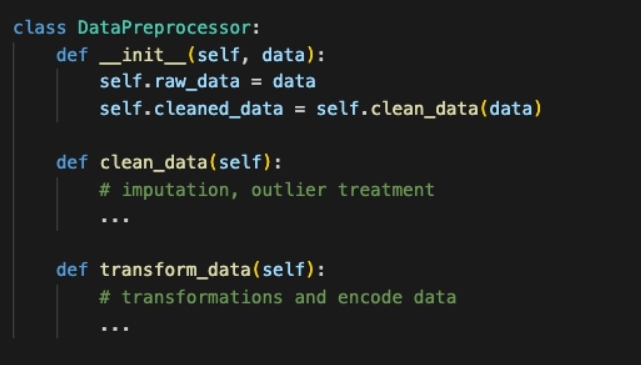
class DataPreprocessor:
def __init__(self, data):
self.raw_data = data
self.cleaned_data = self.clean_data(data)
def clean_data(self):
# imputation, outlier treatment
...
def transform_data(self):
# transformations and encode data
...
class ModelTrainer:
def __init__(self, preprocessed_data):
self.model = self.train_model(preprocessed_data)
def fit(self, preprocessed_data):
# Train a machine learning model
...
def predict(self, preprocessed_data):
# Predict using the machine learning model
...
class ModelEvaluator:
def __init__(self, predictions, actuals):
self.performance_metrics = self.evaluate_model(predictions, actuals)
def evaluate_model(self, predictions, actuals):
# Evaluate model performance
...
def calculate_rmse(self, predictions, actuals):
# Evaluate root mean squared error
def calculate_r_squared(self, predictions, actuals):
# Evaluate r_squared of the model通过将工作流分解为类,可以有更优的结构,并且该结构更易于阅读和维护。每个类都负责处理流程的特定方面。它们可以实例化为:
data_preprocessor = DataPreprocessor('data.csv')
model_trainer = ModelTrainer(data_preprocessor.preprocessed_data)
model_evaluator = ModelEvaluator(model_trainer.model, test_data)在这种情况下,作为一个集成的类,它提供了额外的结构层和灵活性,从而改进了代码的工作流程和可用性。通过充分利用类的功能,本示例创建了一个更加健壮和可扩展的代码库。
重构为类:一个实际的例子
作为一个实际的例子,我最近将3年前在这个存储库中开发的代码重构为一个新的存储库,以显示重构前后代码的差异。
在最初的存储库中,许多功能包括建模任务,因为对几个不同的模型进行了训练和测试。在重构的版本中,有一个包含所有建模任务的模型类SalesForecasting。这更易于阅读,并允许将包更有效地部署为SalesForecasting,并使用不同的输入多次实例化。
类的预览如下所示:
class SalesForecasting:
"""
SalesForecasting class to train and predict sales using a variety of models.
"""
def __init__(self, model_list):
"""
Initialize the SalesForecasting class with a list of models to train and predict.
Args:
model_list (list): list of models to train and predict. Options include:
- LinearRegression
- RandomForest
- XGBoost
- LSTM
- ARIMA
Returns:
None
"""
...
def fit(self, X_train, y_train):
"""
Fit the models in model_dict to the training data.
Args:
X_train (pd.DataFrame): training data exogonous features for the model
y_train (pd.Series): training data target for the model
Returns:
None
"""
...
def __fit_regression_model(self, model):
"""
Fit a regression model to the training data.
Args:
model (sklearn model): sklearn model to fit to the training data
Returns:
model (sklearn model): fitted sklearn model
"""
...
def __fit_lstm_model(self, model):
"""
Fit an LSTM model to the training data.
Args:
model (keras model): keras model to fit to the training data
Returns:
model (keras model): fitted keras model
"""
...
def __fit_arima_model(self, model_name):
"""
Fit an ARIMA model to the training data.
Args:
model_name (str): name of the model to fit to the training data
Returns:
model (pmdarima model): fitted pmdarima model
"""
...
def predict(self, x_values, y_values=None, scaler=None, print_scores=False):
"""
Predict values using the models in model_dict.
Args:
x_values (pd.DataFrame): exogenous features to predict on
y_values (pd.Series): target values to compare predictions against
scaler (sklearn scaler): scaler used to scale the data
print_scores (bool): whether to print the scores for each model
Returns:
self (SalesForecasting): self with updated predictions
"""
...
def __predict_regression_model(self, model):
"""
Predict values using a regression model.
Args:
model (sklearn model): sklearn model to predict with
Returns:
predictions (np.array): array of predictions
"""
...
def __predict_lstm_model(self, model):
"""
Predict values using an LSTM model.
Args:
model (keras model): keras model to predict with
Returns:
predictions (np.array): array of predictions
"""
...
def __predict_arima_model(self, model):
"""
Predict values using an ARIMA model.
Args:
model (pmdarima model): pmdarima model to predict with
Returns:
predictions (np.array): array of predictions
"""
...
def __undo_scaling(self, values, scaler):
"""
Undo scaling on a set of values.
Args:
values (np.array): array of values to unscale
scaler (sklearn scaler): scaler to use to unscale the values
Returns:
unscaled_values (np.array): array of unscaled values
"""
...
def get_scores(self, y_pred, y_true, model_name=None, print_scores=False):
"""
Get the scores for a model. Scores include RMSE, MAE, and R2.
Args:
y_pred (np.array): array of predicted values
y_true (np.array): array of true values
model_name (str): name of the model to get scores for
print_scores (bool): whether to print the scores for the model
Returns:
rmse (float): root mean squared error
mae (float): mean absolute error
r2 (float): r squared
"""
...
def plot_results(self, model_list=None, figsize=p.FIG_SIZE, xlabel="Date", ylabel="Sales", title="Sales Forecasting Predictions"):
"""
Plot the results of the predictions against the actual values.
Generates a timeseries for predictions from each model in model_dict.
Args:
model_list (list): list of models to plot. If None, plots all models in model_dict
figsize (tuple): tuple of figure size
xlabel (str): label for x axis
ylabel (str): label for y axis
title (str): title for the plot
Returns:
fig (matplotlib figure): figure with the plot
"""
...
def plot_errs(self, figsize=(13,3)):
"""
Plot the errors for each model in model_dict. Errors include RMSE, MAE, and R2.
Args:
figsize (tuple): tuple of figure size
Returns:
fig (matplotlib figure): figure with the plot
"""
...类“SalesForecasting”是数据驱动型企业通过应用各种预测模型预测未来销售趋势的综合方案。在本课程中,数据科学家可以利用不同建模技术的力量,包括线性回归,随机森林,XGBoost,LSTM(长短期记忆)和ARIMA(自回归综合移动平均)。通过在这个类中封装预测工作流,模型拟合、预测和评估的过程在不同的模型类型之间变得流线型和一致。通过“SalesForecasting”类,数据科学家可以有效地试验不同的算法,并轻松维护代码库。
面向对象编程是数据科学家构建代码的工具,这些代码反映了他们分析的真实世界系统的复杂性,使他们能够在最大限度地提高敏捷性的同时提取有价值的见解。尽管python打算将类用于实例化和继承,但上面的示例显示了利用类来模块化代码的第一步。随着数据科学能力的扩展和团队的成长,维护高效的代码至关重要。
感谢阅读!你还可以订阅我们的YouTube频道,观看大量大数据行业相关公开课:https://www.youtube.com/channel/UCa8NLpvi70mHVsW4J_x9OeQ;在LinkedIn上关注我们,扩展你的人际网络!https://www.linkedin.com/company/dataapplab/
原文作者:Molly Ruby
翻译作者:文杰
美工编辑:过儿
校对审稿:Chuang
原文链接:https://towardsdatascience.com/object-oriented-data-science-refactoring-code-5bcb4ae7ce72





