
你的散点图和条形图不吸引人?试试这四种方案!
为什么我要写这篇文章?
如果你曾经可视化过你的数据(我相信你这么做过),第一时间出现在你脑海中绘图类型很可能是散点图、条形图或折线图。
也就是下面这个样子:
虽然这些图确实能用在各种各样的可视化数据中,但问题是,它们被太多数据科学家滥用了。
尽管它们简单易懂,但并不是永远的最佳选择。
因此,在这篇文章里,我会介绍一些其他的方案,以及如何更好地使用它们。
请往下读——
如果你想了解更多关于数据可视化的相关内容,可以阅读以下这些文章:
数据可视化的6个等级,快看看你修炼到哪一层了!
强大的 Python Matplotlib 函数——创建漂亮的数据可视化
通过案例数据集,带你了解Python数据分析和数据可视化
Tableau数据可视化,学完就掌握商业分析必备技能了!
01 Hexbin图
散点图的替代方案。
不吹不黑,散点图对于可视化两组数值变量确实非常有用。
但是,当你有成千上万的数据点时,散点图可能会变得过于密集而无法解释。如下所示:
df.plot(kind='scatter',x='x', y='y')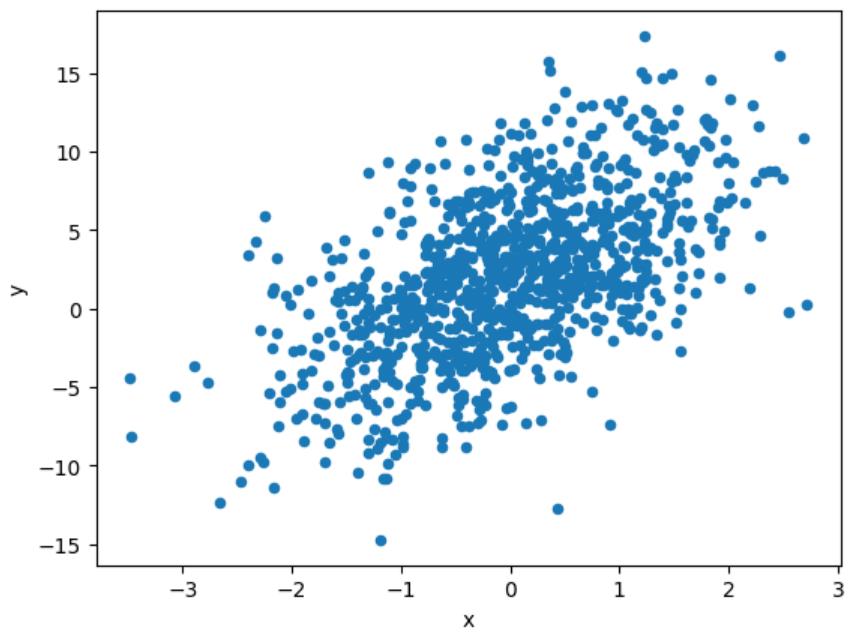
图片和代码来自作者
在这种情况下,Hexbin图是一个不错的解决方案。顾名思义,他们将图表划分为了一个六边形区域。
此外,我们可以基于所使用的聚合方法(例如点的数量),为区域的不同部分添加不同深度的颜色。
df.plot(kind='hexbin', x='x', y='y', gridsize = 13)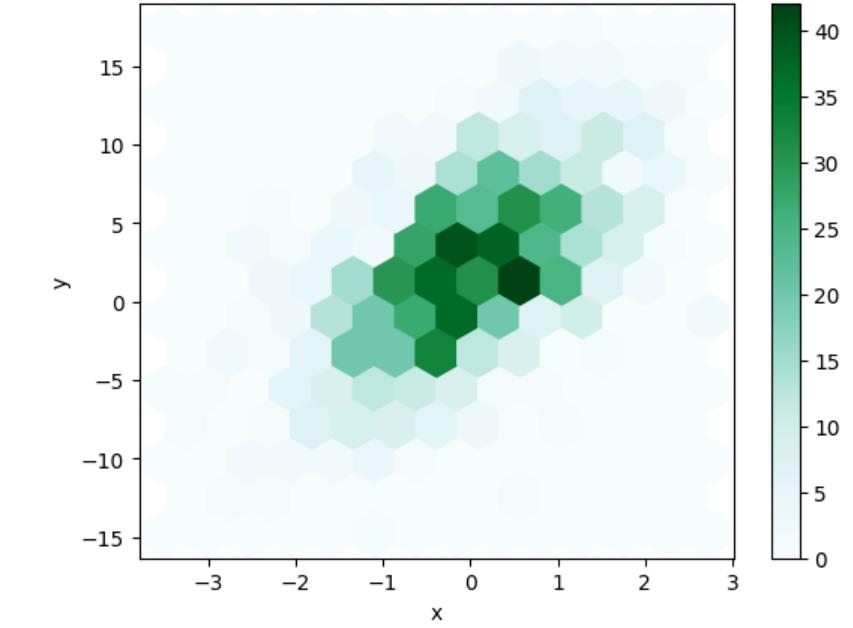
什么时候使用?
Hexbin图最有用的地方在于可以帮助理解数据分布。正因如此,它通常被认为是散点图的一种高级替代方案。
此外,利用数据分箱技术,识别数据集群和描述图案变得更简单了。
02 二维密度图
散点图的另一种替代方案。
正如我们上面所提到的,当数据点太多的时候,用散点图的方式以描绘其分布是非常困难的。
类似于描绘点的密度的Hexbin图,2D密度图描绘了点在二维空间中的分布。
import seaborn as snssns.kdeplot(x=df.x, y=df.y, cmap="Blues", shade=True)
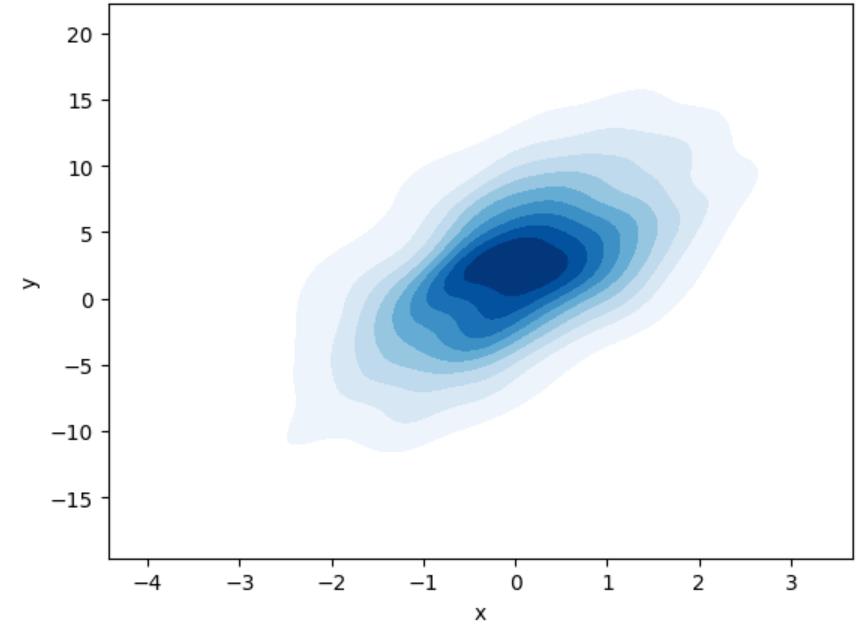
通过连接密度相等的点来描绘线图。换句话说,单个线描绘了相等密度的数据点。
什么时候使用?
如上所述,如果散点图很难描绘,则可以使用2D密度图进行处理。
当你想要识别数据中的模式和异常值时,这种方法特别有用,虽然,散点图的主要作用是描述两个数值变量之间的关系。
03 点图
条形图和折线图的替代方案。
当你需要对连续值分类变量可视化时,条形图非常有用。
但是,当你需要描述很多类别时,由于数据过于密集,条形图的效果可能不尽如人意。
此外,在一个条数众多的条形图里,我们经常会忽略掉单个条的长度,而是会主要观察表示总值的各个端点。
看下面的数据:
df.sample(5)
Year Population Country
17 1996 67 Country B
11 2006 129 Country A
0 1995 92 Country A
16 1995 72 Country B
25 2004 93 Country B这里表示的是1995-2010年间,两个国家(A国和B国)的虚拟人口数量。
让我们创建一个条形图:
import plotly.express as px
fig = px.bar(df, x="Year", y="Population", color="Country")
fig.update_layout(barmode='group')
fig.show()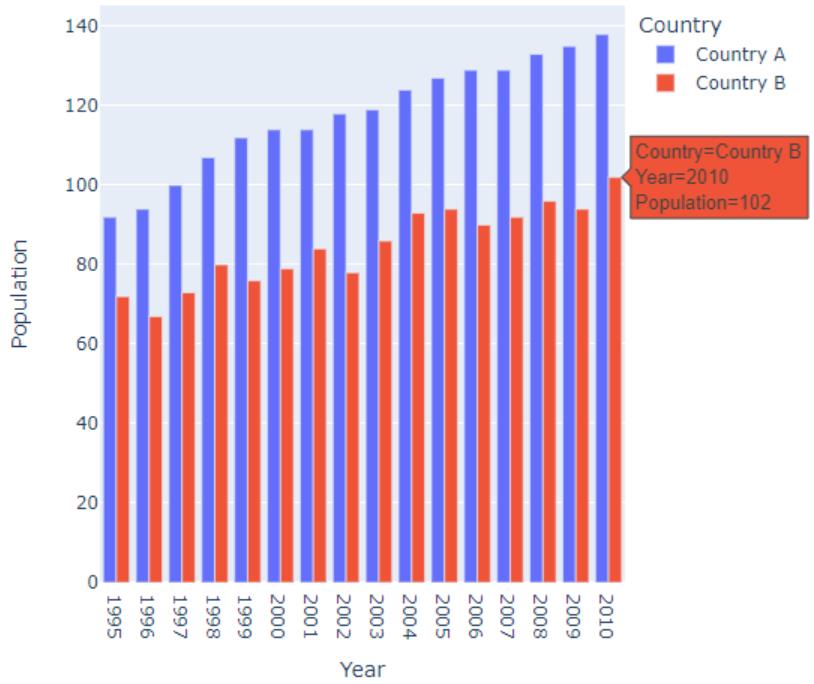
单个条占据了大量的空间,这使得图形看起来很乱。
在这种情况下,点图可能是更好的选择。它很像散点图,但有一个分类轴和一个连续轴。
fig = px.scatter(df, x="Year", y="Population", color="Country")fig.show()
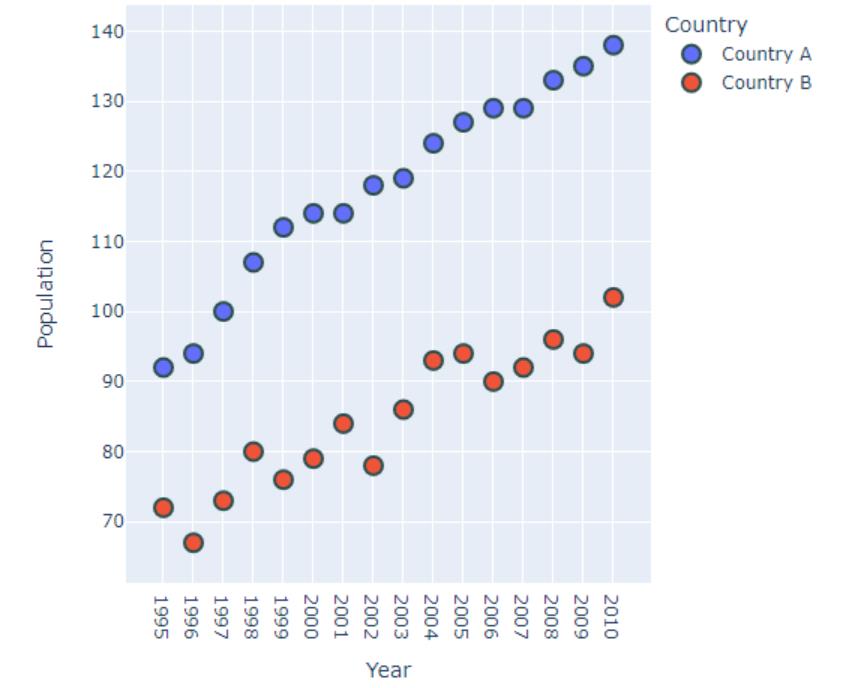
什么时候使用?
与条形图相比,它们不那么杂乱,而且更容易理解。
当我们需要描述多个类别时,它就是不二之选。
04 瀑布图
条形图和折线图的替代方案。
如果你想对一个值“在一段时间内的变化”可视化,折线图(或条形图)并不是万能选择。
折线图和条形图描绘的是图表中的实际值,因此,有时我们很难直观地估计其增量变化趋势。
来看以下数据:
print(df)
Month Value
0 Jan 12.1
1 Feb 11.6
2 Mar 10.4
3 Apr 15.5
4 May 16.7
5 Jun 13.6
6 Jul 16.5
7 Aug 16.0
8 Sep 14.2
9 Oct 12.5
10 Nov 15.6
11 Dec 16.9这里是一份虚拟的月份数据。
我们可以创建一个折线图,如下所示:
df.plot.line("Month", "Value");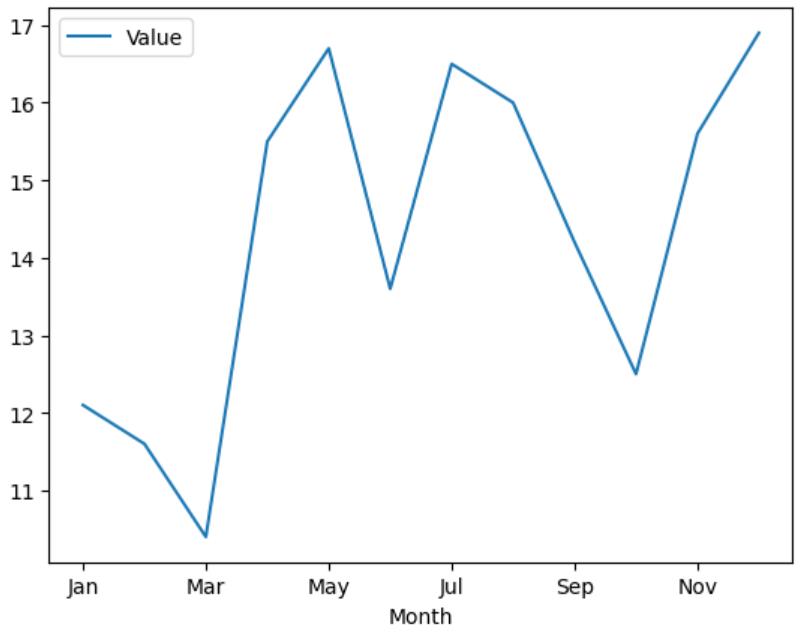
batplot 如下:
df.plot.bar("Month", "Value");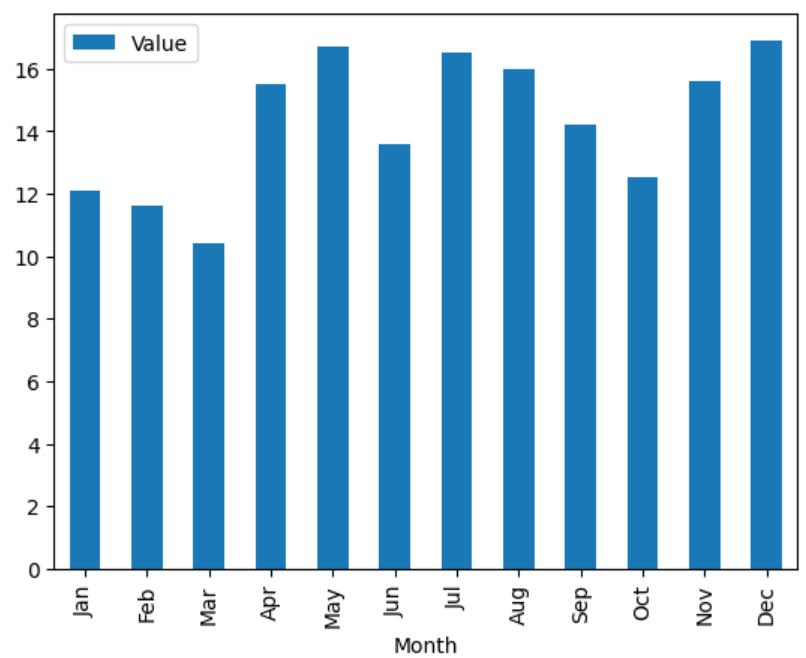
尽管这幅图确实描述了所需的数据,但我们很难直观地估计其中的滚动变化趋势。
想要解决这个问题,你可以使用瀑布图。
我们可以利用Python中的waterfallcharts库。
!pip install waterfallcharts接下来,我们应找到滚动差值,并将其表示在一个新列中。最终数据应如下所示:
print(df)
Month Value Delta
0 Jan 12.1 12.1
1 Feb 11.6 -0.5
2 Mar 10.4 -1.2
3 Apr 15.5 5.1
4 May 16.7 1.2
5 Jun 13.6 -3.1
6 Jul 16.5 2.9
7 Aug 16.0 -0.5
8 Sep 14.2 -1.8
9 Oct 12.5 -1.7
10 Nov 15.6 3.1
11 Dec 16.9 1.3第一个月的增量值与开始值相同。
import waterfall_chartwaterfall_chart.plot(df.Month, df.Delta)
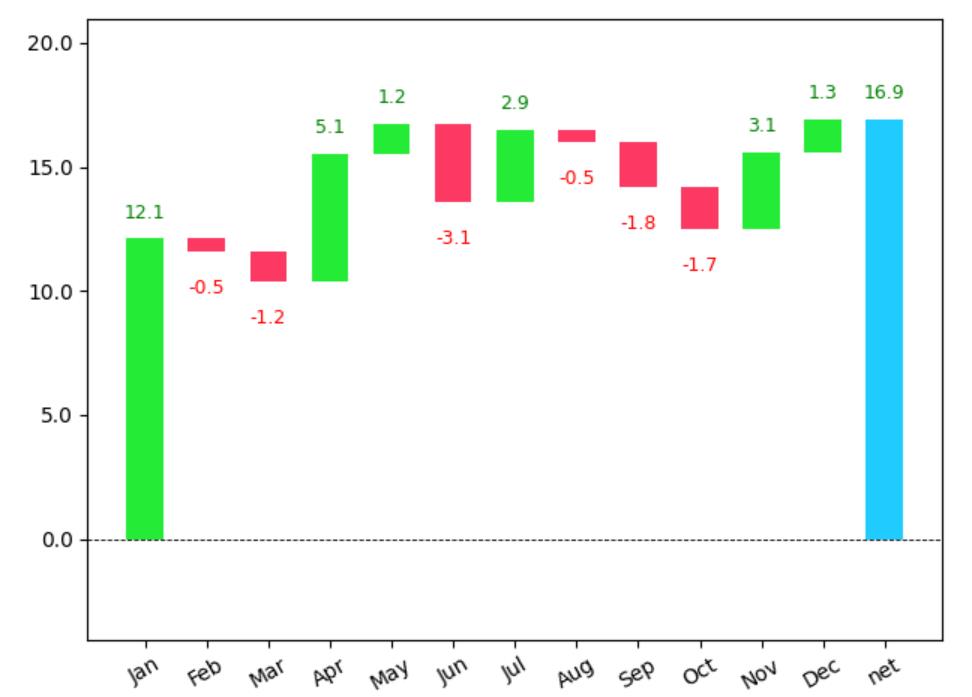
这样看起来好多了,不是吗?
我们可以看到,开始值和最终值由第一条和最后一条表示。此外,边际变化会自动用颜色编码,使其更加直观。
什么时候使用?
当你需要描述单个步骤对总价值的增量贡献,以及这些贡献如何随时间变化的,瀑布图非常有用。
结语
恭喜,从此以后你的可视化方案中又多了4个绝对会让你爱不释手的方案图。
我还要讲一句,要明白,我们把数据可视化为的是让数据更耐看、更直观,因此,根据你的目标,选择视觉效果最好的方案图。
另外,我写这篇文章可不是为了批驳这三种最基本的可视化方案图,相反,我希望的是,你可以拥有更多的选择。
感谢你的阅读!你还可以订阅我们的YouTube频道,观看大量大数据行业相关公开课:https://www.youtube.com/channel/UCa8NLpvi70mHVsW4J_x9OeQ;在LinkedIn上关注我们,扩展你的人际网络!https://www.linkedin.com/company/dataapplab/
原文作者:Avi Chawla
翻译作者:高佑兮
美工编辑:过儿
校对审稿:Chuang
原文链接:https://towardsdatascience.com/unimpressed-with-your-scatter-and-bar-plots-give-these-four-classic-alternatives-a-try-a3bab20d4872





