
如何在机器学习面试中脱颖而出:我的个人攻略
准备好参加大型科技公司或初创公司的机器学习面试了吗?从测试你的广博知识到深入研究具体问题、系统设计和编码挑战,所有不同的回合都会让你感到不知所措。刚开始的时候,我觉得完全迷失了方向,不得不深入挖掘,拼凑出合适的资源。
这就是我写这篇文章的原因——分享帮助我的资源,这样你就不必在类似的困惑中挣扎,可以自信地应对你的机器学习面试。如果你想了解更多关于面试的相关内容,可以阅读以下这些文章:
数据分析师求职面试中需要注意的危险信号
大厂资深面试官:我最喜欢问应聘者的编程问题(以及原因)
你在准备FAANG/MAANG面试时可能犯的最大错误
为什么我在数据科学面试中没有做好准备?
注意:本文不会涉及一般的软件工程面试,比如DSA编码,或者像数据分析师这样的专业角色,这些面试的重点是SQL或数据相关的问题。
我们开始吧。
四种类型的回合:
- 机器学习广度:这一轮测试你在各种机器学习主题上的广博知识。我通常把35%的准备时间花在这里。
- 机器学习深度:这一轮需要我大约25%的准备时间,专注于专业主题和详细的案例研究。
- 机器学习系统设计:这一轮评估你设计可扩展机器学习系统的能力。我在这里分配了大约40%的准备时间。
- 机器学习编码:在这一轮中,你将解决围绕基本算法的编码挑战。由于这种情况很少发生,所以我只花了0-10%的准备时间(与广度分享)。
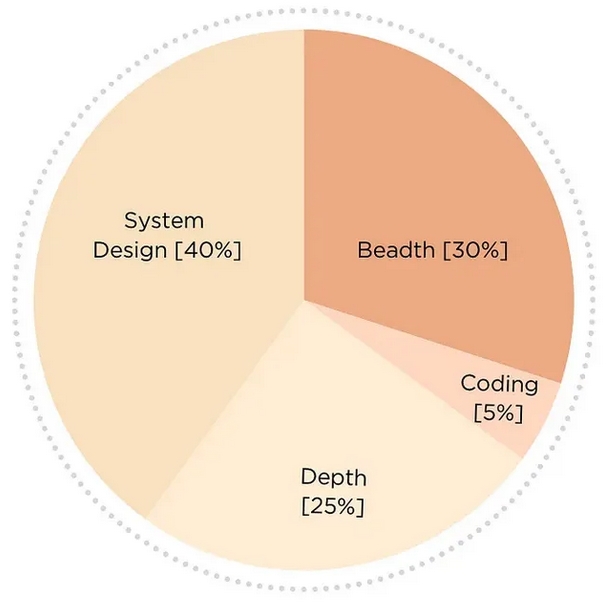
注意:这个细分会根据你的经验水平和背景而有所不同。调整你的准备策略,以适合你的需要。
机器学习广度✦
这一轮评估工程师对各种主题的机器学习基础知识的理解。面试通常是一个快速的环节,面试官可能会在不同的话题之间切换,或者可能会在一个领域问一些一般性的问题。
一个常见的错误是完全依赖在线调查问卷。面试官经常会重新构思问题,这使得深入理解概念变得至关重要。例如,我曾经被问到如何处理用户单击数据集中的不平衡类(其中一个类,如用户单击,比另一个类少得多)。我建议使用“重采样”,这可能会扭曲数据集分布并影响模型的准确性。相反,对于大型数据集,最好不要改变数据分布。
话题可能因公司类型或业务需求而异。“例如,自动驾驶公司可能会要求面试者具备计算机视觉的基础知识,无论是初级还是高级职位。”
基础主题(各级)
- 监督学习:分类(逻辑回归、支持向量机、决策树)、回归(线性回归和岭回归)
- 无监督学习:聚类(k-means,分层,DBSCAN),降维,潜在语义分析(LSA)
- 集成方法:随机森林(套袋),梯度增强机
- 深度学习:Multi-layer Perceptron, CNNs
- 模型评估指标:分类与回归评估指标,偏差与方差权衡
- 损失函数:不同类型的损失函数,正则化,过拟合与欠拟合
- 特征选择和重要性:识别重要特征的技术,如相关分析、递归特征消除、套索
- 统计学:p值,r平方,回归分析,朴素贝叶斯,分布,最大似然估计,A/B测试
专题(高级/专业角色)
时间序列和顺序数据:
rnn, lstm, Seq2Seq模型:理解为处理时间相关和顺序数据而设计的架构。
参考资料:rnn、lstm和Seq2Seq模型的优秀教程(https://www.datacamp.com/tutorial/tutorial-for-recurrent-neural-network)
自然语言处理:
- 单词嵌入:Word2Vec、GloVe等技术
- 注意机制和变压器模型
- LLM基础:变得越来越相关
推荐阅读的文章:
- 一个傻瓜的Word2Vec指南:https://medium.com/@manansuri/a-dummys-guide-to-word2vec-456444f3c673
- 变形金刚和注意力机制:https://medium.com/@kalra.rakshit/introduction-to-transformers-and-attention-mechanisms-c29d252ea2c5
强化学习:
与机器人公司职位相关
资源:强化学习概述,教程:https://towardsdatascience.com/reinforcement-learning-101-e24b50e1d292
后续步骤:
一旦你理解了基本原则,就可以用面试样题进行练习。
- GeeksforGeeks:机器学习面试问题https://www.geeksforgeeks.org/machine-learning-interview-questions/
- GitHub:ML问题https://github.com/andrewekhalel/MLQuestions?tab=readme-ov-file
- 目的:机器学习面试问题https://aiml.com/top-100-machine-learning-interview-questions/
机器学习深度:
这一轮面试特别有趣,也是所有面试类型中最开放的一轮。一般是针对有一定经验的初级以上工作。这次面试的目的有三个:
- 对特定问题空间的理论和实践理解
- 设计一个有效的实验并分析结果
- 沟通技巧
希望面试官在这个领域有丰富的背景知识。虽然为这一轮面试做专门的准备很有挑战性,但了解面试的大致方向会有所帮助。下面是一些面试中常见的方向:
- 过去的经历:讨论你的学术或工业项目以及它们的缺点。准备好详细讨论你的项目。
- 理论背景:深入研究一个专业领域的理论方面,特别是如果这个角色需要这种专业化。
一些专业化的例子及其有用的资源:
自然语言处理:
- NLP的高级技术:https://medium.com/analytics-vidhya/natural-language-processing-advance-techniques-in-depth-analysis-b67bca5db432
- 由Pratik Bhavsar撰写的NLP代谢日志:https://pakodas.substack.com/p/nlp-metablog-a-blog-of-blogs-693e3a8f1e0c
- LLM概述Maxime Labonne:https://github.com/mlabonne/llm-course?tab=readme-ov-file
计算机视觉:
- Coursera:计算机视觉基础:https://www.coursera.org/learn/computer-vision-basics
强化学习:
Github:强化学习概述:https://lilianweng.github.io/posts/2018-02-19-rl-overview/
学习排名:
时间序列预测:
时间序列预测的完整指南:https://medium.com/@wainaina.pierre/the-complete-guide-to-time-series-forecasting-models-ef9c8cd40037
机器学习系统设计:
这一轮类似于典型的软件工程系统设计面试,应用了类似的原则。你被赋予一个产品空间(例如,设计一个YouTube推荐ML系统),并被要求定义问题,概述设计过程,并传达你的想法,包括权衡。
面试官看重的是你解决问题的方法、思维过程和高层次的设计技能。在面试过程中,你可能会被要求深入了解具体的组成部分。一般来说,大多数机器学习系统可以分解为5个关键组件。以下是每个组件的主要关注点:
(1️)问题定义
清楚地定义问题并制定你的假设。
(2️)评估指标
- 理解模型性能指标和业务指标之间的区别。
- 模型指标:精度、召回率、均方误差等。
- 业务指标:收入、点击次数、检测到的欺诈次数等。
(3️)特性和数据
处理离线和实时数据流管道,并预处理原始数据以创建功能。
(4️)模型开发
培训:
选择合适的模型,并讨论模型选择背后的基本原理。提供培训过程的详细信息(一次性、经常性、在线培训)。
评价:
选择评估数据集,有效评估模型性能。
(5️)推理服务与部署
制定部署策略,包括技术的选择和确保推理服务的可伸缩性。讨论自动化部署、评估和A/B测试的方法。
机器学习编码:
我只遇到过一次专门针对机器学习的编码。这轮融资并不常见,但在初创企业中更为常见。除非特别提到,否则我一般不会准备。一定要和招聘人员确认,在任何一轮面试中是否会有ML编码问题。如果没有,那就把准备的重点放在其他部分。如果有一个特定的ML编码轮,重新分配一些时间从ML广度来练习编码几天。策略很简单:将ML编码准备与ML广度的基础知识合并,为基本模型练习编码。
资源:
- Neetcode:机器学习编码问题https://neetcode.io/practice?subpage=practice&tab=coreSkills&topic=Machine+Learning
- Github:100天的ML代码https://github.com/Avik-Jain/100-Days-Of-ML-Code?tab=readme-ov-file
- Kaggle:人们分享代码的好平台。例如,房价预测使用tfff:https://www.kaggle.com/code/gusthema/house-prices-prediction-using-tfdf
- AlgoExpert:对于视觉学习者,请查看AlgoExpert的ML编码问题。我试过一次,发现很有用。https://www.algoexpert.io/machine-learning/coding-questions
总结
准备机器学习面试可能是一个充满挑战的旅程,但有了正确的资源和计划,你可以自信地驾驭它。记住,每次面试都是一次学习的经历,让你离理想的工作更近一步。保持好奇,不断学习。好运!
最后,我想分享一些资源供大家参考:
- 快速修改的ML备忘单https://sites.google.com/view/datascience-cheat-sheets
- ML访谈书,Chip Huyen著https://huyenchip.com/ml-interviews-book/
免责声明:本文基于个人经历和公共资源。请注意,本文仅代表个人观点,不代表作者过去或现在雇主的观点。一定要参考招聘公司的官方资源,以获得最准确的信息。
感谢阅读!你还可以订阅我们的YouTube频道,观看大量大数据行业相关公开课:https://www.youtube.com/channel/UCa8NLpvi70mHVsW4J_x9OeQ;在LinkedIn上关注我们,扩展你的人际网络!https://www.linkedin.com/company/dataapplab/。
原文作者:Kartik Singhal
翻译作者:过儿
美工编辑:过儿
校对审稿:Jason
原文链接:https://medium.com/@kgk.singhal/how-to-ace-machine-learning-interviews-my-personal-playbook-a75794155157



