
kaggle模拟人力资源数据——如何预测员工失业率?
原文作者:Imad Dabbura
原文链接:https://towardsdatascience.com/predicting-employee-turnover-7ab2b9ecf47e
翻译:Xin Qin
介绍
员工流失率是指离职并被新人代替的员工比例。员工流失会给企业带来成本,包括但不限于:空缺,招聘,培训和替换。平均而言,企业需要花费四周到三个月时间对新员工进行培训。如果新员工入职第一年就离职,对于公司而言是一种损失。更有甚者,一些公司例如咨询机构会面临客户满意度下降的问题,由于咨询顾问的频繁变更可能导致业务损失。
在这篇文章中,我们将从kaggle中选择模拟人力资源数据,建立一个分类器,帮助我们预测在给定属性的情况下,哪些员工更可能离职。这样的分类器将有助于企业预测员工流失率,并帮助解决带来的高成本。我们将使用最常见的分类器:随机森林(RandomForest),渐变增强树(Gradient Boosting Trees),临近算法(K-NearestNeighbors),Logistic回归和支持向量机(SupportVector Machine)。
数据有14,999个样本。以下是每个特征及其定义:
•satisfaction_level:满意度{0-1}。
•last_evaluationTime:距离上次绩效评估的时间(以年为单位)。
•number_project:在工作中完成的项目数量。
•average_montly_hours:每月平均在职小时数。
•time_spend_company:在职年份。
•Work_accident:员工是否有工作场所事故。
• left:员工是否离职{0,1}。
•promotion_last_5years:这个员工在过去的五年里是否晋升。
•sales:员工工作的部门。
•salary:相对工资水平{低,中,高}。
1 数据处理
我们先来检查数据(是否有缺失值和每个特征的数据类型):

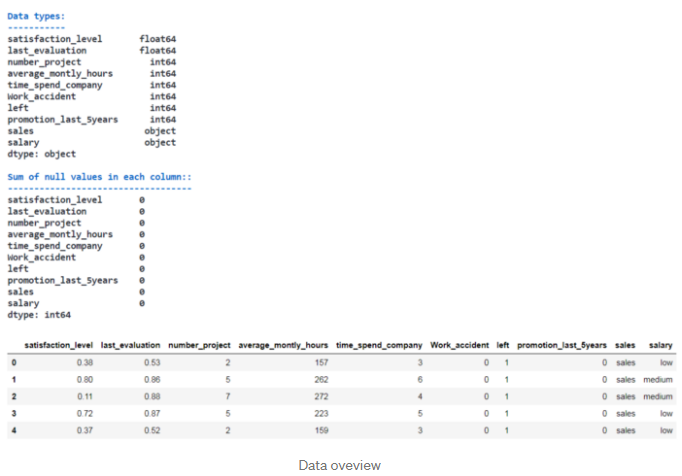
由于没有缺失值,我们不需要做任何填补。 但是,需要做一些数据预处理:
1.将sales名称更改为department。
2.把salary转换成有序分类的特征(ordinalcategorical feature),因为低,中,高之间有内在秩序。
3.从department中创建虚拟特征(dummyfeatures),去掉第一个虚拟特征以避免一些学习算法可能出现的线性依赖。

数据现在可以用于建模了。最终特征的数量是17。
2 建模
我们先来看看每个类(class)的比例,看看我们是在处理平衡数据还是不平衡数据,因为在拟合分类器(classifiers)时,每个类都有自己的一套工具。
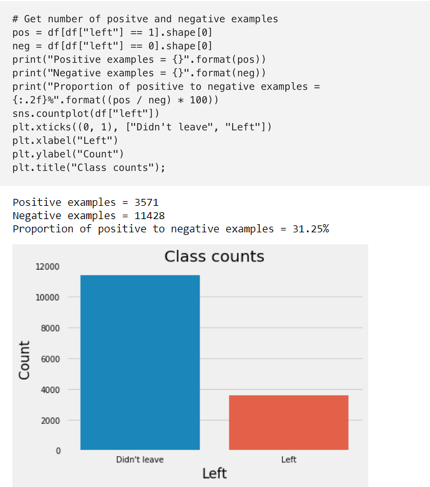
如图所示,我们的数据集不平衡。因此,当我们在这些数据集上使用分类器时,比较f1-score或AUC(ROC曲线下的面积)等模型时,我们应该使用准确度以外的度量。而且,在训练过程中,类的不平衡会影响学习算法,即学习基于数据集中的多数类来优化预测的模型,使决策规则偏向大多数类。有三种方法可以解决这个问题:
1.对少数群体的错误预测给予较大的惩罚。
2.提高少数群体的抽样或降低多数人群的抽样数量。
3.生成合成训练样本。
尽管如此,我们没有明确的指导或最佳实践来处理这种情况。因此,我们需要尝试看看哪一个最适合。我们将限制自己使用前两个,即用分类器中的class_weight对少数类的错误预测分配较大的惩罚,并且评估训练数据的上采样/下采样(upsampling/downsampling),看哪个表现更好。
首先,使用80/20法则将数据分到训练和测试集中;80%的数据将用于训练模型,20%用于测试模型的表现。其次,对少数类上采样,对多数类下采样。对于这个数据集,正面类(positiveclass)是少数类,负面类(negative class)是多数类。

Original shape: (11999, 17) (11999,)
Upsampled shape: (18284, 17) (18284,)
Downsampled shape: (5714, 17) (5714,)
我不认为我们需要应用像PCA这样的降维,因为:
1)我们想知道每个特征在决定谁将离开与否中的重要性。
2)数据集的维度是合理的(17个特征)。 但是,最好还看看需要多少主成分来解释90%,95%和99%的数据方差(variation)。
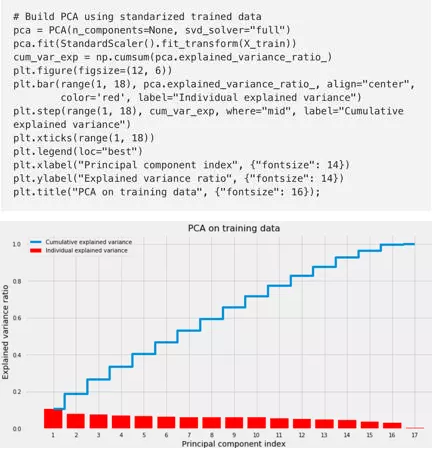
看来需要14,15和16个主成分来分别捕获90%,95%和99%的数据方差。换句话说,这意味着数据已经比较合理,因为特征值彼此非常接近,并进一步证明我们不需要压缩数据。
我们在构建分类器时要遵循的方法如下:
1.使用scikit-learn的make_pipeline来处理分类器时构建一个pipeline处理所有的步骤,这将有两步:
- 标准化数据,使所有特征处于同一规模。
- 我们要使用来拟合模型的分类器(估计器)。
2.使用GridSearchCV使用10倍交叉验证来调整超参数。我们可以使用RandomizedSearchCV,它的速度更快,可能会超过GridSearchCV,尤其是当我们有两个以上的超参数时,每个参数的范围都很大。然而,由于我们只有两个超参数和缩小的范围,GridSearchCV的效果一般。
3.使用训练数据拟合模型。
4.使用测试数据绘制混淆矩阵(confusion matrix)和ROC曲线以得到最佳估计量。
对随机森林,Gradient Boosting Trees,邻近算法,Logistic回归和支持向量机重复以上步骤。接下来,选择交叉验证(crossvalidation )f1得分最高的分类器。
3 随机森林
首先,我们将使用未抽样,上采样和下采样数据拟合一个随机森林分类器。 其次,我们将使用交叉验证(CV)f1评分来评估每种方法,并选择具有最高CV f1评分的方法。 最后,我们将使用该方法来匹配其他分类器。
我们将调整的唯一超参数是:
max_feature:在每次分割中随机考虑多少个特征。 这将有助于避免在每次分割中选择少量强大的特征,让其他特征有机会起作用。因此,预测的相关性会降低,每棵树的方差也会降低。
min_samples_leaf:每次拆分有多少个例子成为最终的叶节点(leafnode)。
随机森林是一个有多个树(n_estimators)的集合模型。 最终预测将是所有估计者的预测的加权平均(回归)或模式(分类)。 注意:大量树不会导致过度拟合(overfitting)。

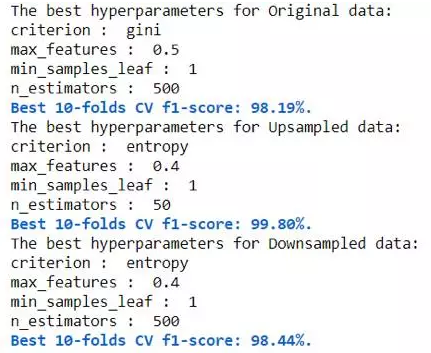
上采样产生最高的CV f1得分99.8%。 因此,我们将使用上采样数据来适应其他分类器。 新的数据现在有18284个例子:50%属于正面类,50%属于负面类。
我们使用上面调整的最佳超参数来修改具有上采样数据的随机森林,并使用测试数据绘制混淆矩阵和ROC曲线。
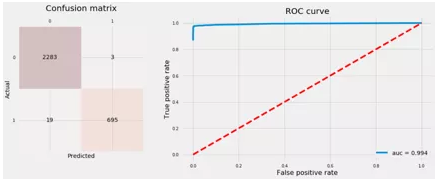
4 渐变增强树
渐变增强树与随机森林相同,除了:
- 从小树开始,通过考虑生成的树的residual,从生成的树开始。
- 更多的树会导致过度拟合; 与随机森林相反。
所以我们可以把每一棵树看作一个弱学习者。 除了max_features和n_estimators之外,我们要调整的另外两个超参数是:
- learning_rate:树学习的速度,越慢越好。
- max_depth:每次树增长时分割的数量,这限制了每棵树中节点的数量。
使用测试数据来拟合GB分类器并绘制混淆矩阵和ROC曲线。
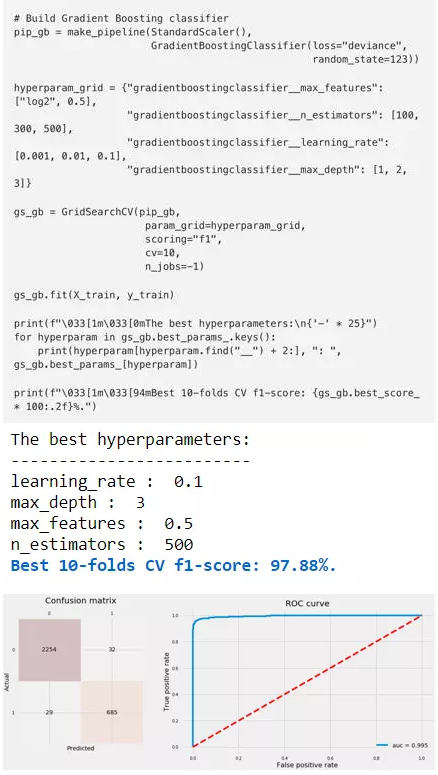
5 临近算法
KNN被称为懒学习算法,因为它不学习任何参数。我们要调整的两个超参数是:
- n_neighbors:在预测中使用的邻居数量。
- 权重:基于以下因素分配邻居的权重:
- “uniform”:所有相邻点具有相同的权重。
- “distance”:使用预测中使用的每个相邻点的欧氏距离(euclideandistance)的倒数。
我们来拟合KNN分类器,绘制混淆矩阵和ROC曲线。
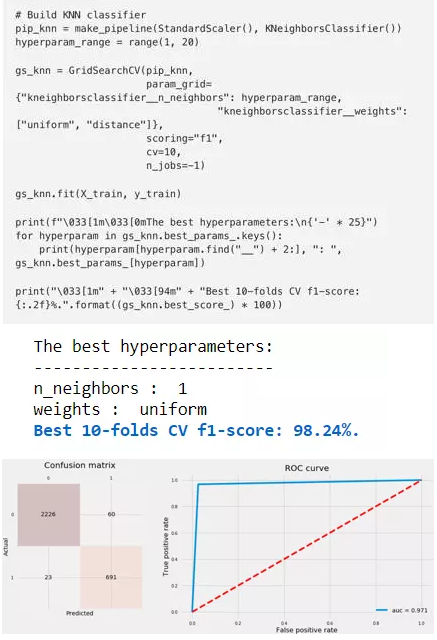
6 Logistic回归
对于Logistic回归,我们将调整三个超参数:
- penalty:正规化(regularization)类型,L2或L1正则化。
- C:与参数λ的正则化相反。C越高,正规化越少。 我们将使用覆盖非正则化到完全正则化的全部范围的值,其中模型是样本标签的模式。
fit_intercept:是否包含拦截。
我们不会使用任何非线性,如多项式特征(polynomialfeatures)。
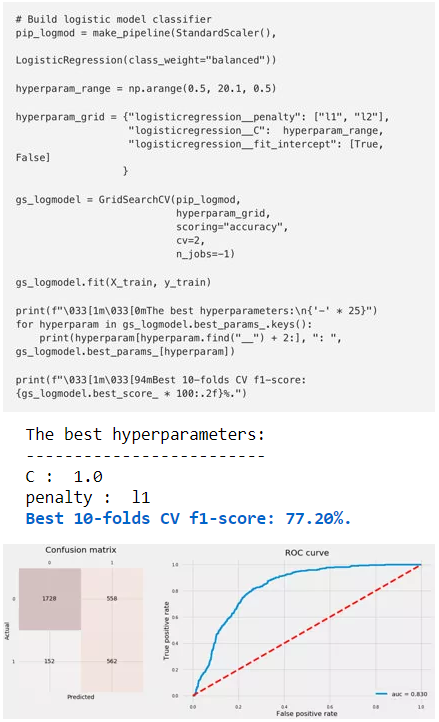
7 Support Vector Machine
支持向量机(SVM)
由于两个原因,SVM对于超参数的调整是非常昂贵的:
1.对于大的数据集,它变得非常缓慢。
2.有很多超调参数需要很长时间才能调整CPU。
因此,我们将使用我们之前提到过的超参数值来得出Penn MachineLearning Benchmark 165数据集的最佳表现。我们通常要调整的超参数是:
C, gamma, kernel, degree and coef0

The 10-folds CV f1-score is: 96.38%
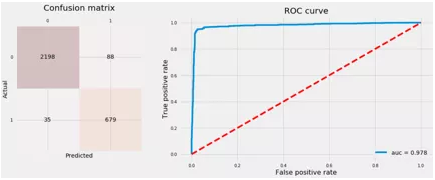
8 结论
最后列出我们迄今为止训练过的所有分类器的测试准确率并绘制ROC曲线。 然后我们将选择ROC曲线下面积最大的分类器。
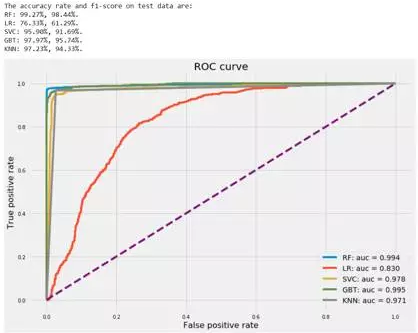
即使随机森林和梯度提升树具有几乎相等的AUC,随机森林具有更高的准确率和f1分数,分别为99.27%和99.44%。 因此,我们有理由说随机森林胜过了其他的分类器。 让我们来看看随机森林分类器中的特征重要性。
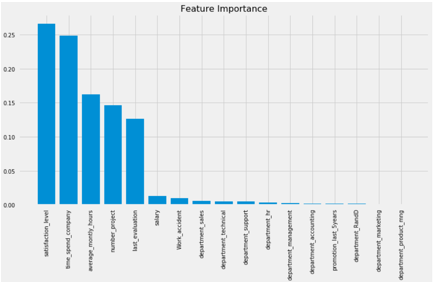
最重要的五个特点是:
• satisfaction_level
• time_spend_company
• average_montly_hours
• number_project
• lats_evaluation
我们可以得到的结论是:
- 在处理不平衡类别时,准确性不是用来评估模型的好方法。 我们可以使用AUC和f1-score。
- 上采样/下采样,数据合成和使用平衡类别权重是尝试提高不平衡类别数据集分类器准确度的好方式。
- GridSearchCV可以帮助调整每个学习算法的超参数。RandomizedSearchCV速度更快,甚至可能超过GridSearchCVes,尤其是当我们有两个以上的超参数要调整时。
- 主成分分析(PCA)并不总是被推荐,特别是如果数据处于良好的特征空间(featurespace),并且它们的特征值彼此非常接近。
- 不出所料,集合模型(ensemble models)在大多数情况下都优于其他学习算法。





