
LLM 生态系统指南
一个围绕LLMs的庞大生态系统正在形成,跟上这一切可能是一项挑战。本文通过阐明生态系统的核心组成部分,为混乱带来了一些秩序。如果你想了解更多关于LLM的相关内容,可以阅读以下这些文章:
如何使用Code Llama构建自己的LLM编码助手
LLMs能否取代数据分析师?
LeMA:对于一个LLM来说,学习数学就是在犯错!
ChatGPT和LLM的10个关键术语和概念
模型(LLMs)-核心组件
大型语言模型(LLMs)是我们使用的许多人工智能应用程序背后的原材料。在围绕这些模型的炒作之下,它们只是具有(非常)大量参数的数学函数。最小的模型大约有15亿个参数,而一些较大的模型(如Falcon)大约有1800亿个参数。
据传闻,Chat-GPT(付费版本)背后的LLM GPT-4大约有1.4万亿个参数。
这些模型最初被预先训练来预测句子中的下一个单词。这种“不那么明显”的特性是,人们可以微调下游以遵循指示,这可能是回答问题、进行对话和推理(如Orca-2的情况)。
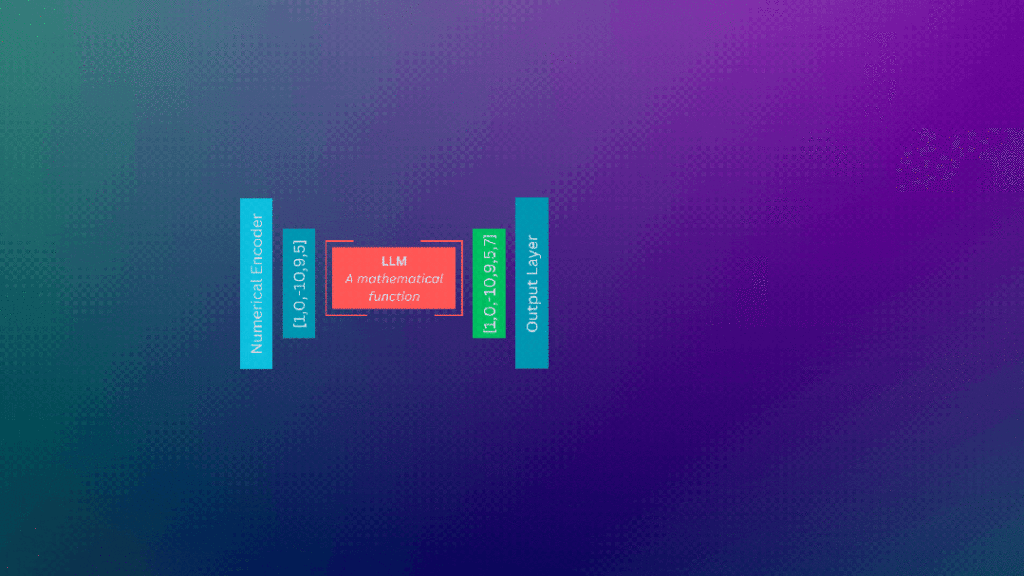
这种微调使它们对今天的应用程序很有用,比如ChatGPT、GitHub Copilot、Bard Claude2等。
当我们要求LLM执行诸如回答问题或与我们交谈之类的任务时,我们对该LLM执行推理。我们将在后面更多地讨论推理的重要性!
请观看对OpenAI联合创始人Ilya Sutskever的精彩访谈,他在访谈中揭示了从LLM训练中获得的惊人见解。
计算基础设施——运营骨干
LLMs只是具有大量参数的数学函数。当我们对LLM执行推理时,我们进行数学运算,LLMs的庞大规模意味着许多这些数学运算!
执行这些操作需要专门的GPU(图形处理单元)。GPU擅长并行执行数学运算,这是实现使用LLMs所需运算的有效方式。
合适的GPU很难获得;你甚至可能会发现你的笔记本电脑没有合适的GPU。人工智能工程师利用Runpod, UbiOps等计算平台,甚至是允许他们租用GPU运行LLM工作负载的云平台。
Hugging Face — LLM的家居用品店
Hugging Face是你关于LLMs的一站式开源商店,提供大量LLM实用工具
基础模型:你可以获得大多数可用的开源基础LLM。使用LLM所需的一切,从模型权重(模型文件)到许可证,都可以在Hugging Face储存库中找到。
这是Mixtral的链接,这是由Mistral AI发布的一款优于GPT-3.5 Turbo的模型。
AutoTrain:想要对你的LLMs进行微调吗?Hugging Face也提供了这样的平台!你可以使用AutoTrain平台作为一个无代码解决方案来为你的模型进行微调。它管理计算基础设施,允许你按小时租用GPU进行训练工作,但你必须提供自己的数据!
- 排行榜:有这么多LLMs可供选择,你如何选择最合适的?你可以利用Hugging Face排行榜来比较LLM的性能。Open LLM排行榜将基础模型的性能与基准进行比较。而Chatbot Arena则比较了作为聊天机器人的模型的性能。
- 数据集:你可以通过Hugging Face访问数据集,甚至可以将其用作数据存储库。如果你正在寻找数据来评估或微调你的LLM,你可以从这里开始。
- 空间:我已经利用了空间,快速与客户进行演示。Hugging Face提供了快速部署演示所需的计算和必要的基础设施。
- Python API:这些服务位于其API的后面,可以通过编程方式访问。Hugging Face代码库是开源的,可以在GitHub上获得。
Hugging Face还有更多的功能,它是开源LLM开发的核心——对任何人工智能工程师来说都是无价的资源。
专有LLMs服务-开箱即用的LLMs
随着OpenAI、Anthropic和Mistral AI的推出,可用的专有 LLM 服务的数量似乎也在不断增长。专有服务使你可以轻松开发LLM应用程序;你不必担心自己在Runpod等服务上托管模型;这些都由供应商为你处理。这种便利程度也存在一些权衡。
你不拥有任何模型或基础设施;因此,你将受到提供商对其模型的更新甚至公司政策的摆布。
2023年OpenAI领导层的问题让许多人担心该公司会崩溃,从而影响到他们在OpenAI基础上构建的任何产品。
你的数据被转移到第三方和潜在竞争对手;这可能不适合处理敏感数据的用例。尽管如此,专有模型仍然是性能最好的模型(在撰写本文时)。
推理和模型服务-交付系统
推理服务器只适用于在开源基础LLMs上进行开发的情况,你可能会从Hugging Face获得这种服务器。如果LLM是一架飞机,那么推理服务器就是跑道。在构建应用程序时,它们(几乎)是使用开源LLMs所必需的。这有几个原因:
- 效率:推理服务器有效地在LLMs上运行推理,提高了模型吞吐量。vLLM就是一个很好的例子;它使用页面关注来分割查询,从而使吞吐量最大化。在构建计划扩展的应用程序时,效率意味着节省成本!
- 互操作性:许多LLM应用程序开发框架最初是为了与OpenAI API配合使用而设计的。因此,集成你的开源LLMs可能具有挑战性。推理服务器通过提供与LLM应用程序开发框架集成的方便端点解决了这个问题。
应用程序开发-创建工具
许多人已经熟悉了生态系统的这一部分。LangChain、LlamaIndex、Haystack和AutoGen等框架都属于这一类。它们都有一个共同点:它们提供函数和类,帮助你构建LLM驱动的应用程序的组件。例如,如果希望开发聊天机器人,可以利用LlamaIndex中的聊天引擎包装器。或者,如果你想构建多代理工作流程,你可以选择AutoGen的GroupChat。这些框架本质上是即插即用的;你带来了LLMs(可能是专有的或开源的),你得到了开发应用程序所需的功能。
前端-用户界面
前端或UI对于任何LLM驱动的应用程序来说都是锦上添花,这通常是一些聊天界面。
当然,并非所有应用程序都需要聊天界面前端;GitHub copilot就是一个很好的例子;它直接集成到你的交互式开发环境中。但是,对于确实需要的应用程序,正在出现解决方案,可以使用最少的代码在你的应用程序上添加聊天界面。
Chainlit就是一个例子,它可以很好地与应用程序开发框架集成,是可定制的,并且可以使用多模态模型。Streamlit是另一个受欢迎的选择。
结论
现在,你应该对LLM生态系统有了更清晰的了解,以及它如何在设计应用程序时为你的目的服务。生态系统正在迅速发展。然而,即使出现新的服务提供商,本文中概述的原则也可能在可预见的未来保持相关性。
感谢阅读!你还可以订阅我们的YouTube频道,观看大量大数据行业相关公开课:https://www.youtube.com/channel/UCa8NLpvi70mHVsW4J_x9OeQ;在LinkedIn上关注我们,扩展你的人际网络!https://www.linkedin.com/company/dataapplab/
原文作者:John Adeojo
翻译作者:文玲
美工编辑:过儿
校对审稿:Jason
原文链接:https://pub.aimind.so/your-guide-to-the-llm-ecosystem-f67826c84be8





